Ese código crea en el escritorio un archivo de texto con la lista de juegos, uso dos veces la expresión regular (re) porque a la derecha hay otra lista pero que no entra en el criterio solicitado
mmm... aparte también está el problema de que las X filas varían XD, creo que lo más fácil es abrir la Consola del Navegador y pegar un Script que extraiga los textos que quieres
Código
var span = document.querySelectorAll("#listing-games span.title")
var txt =""
for(var el of span) txt += el.textContent+"\n"
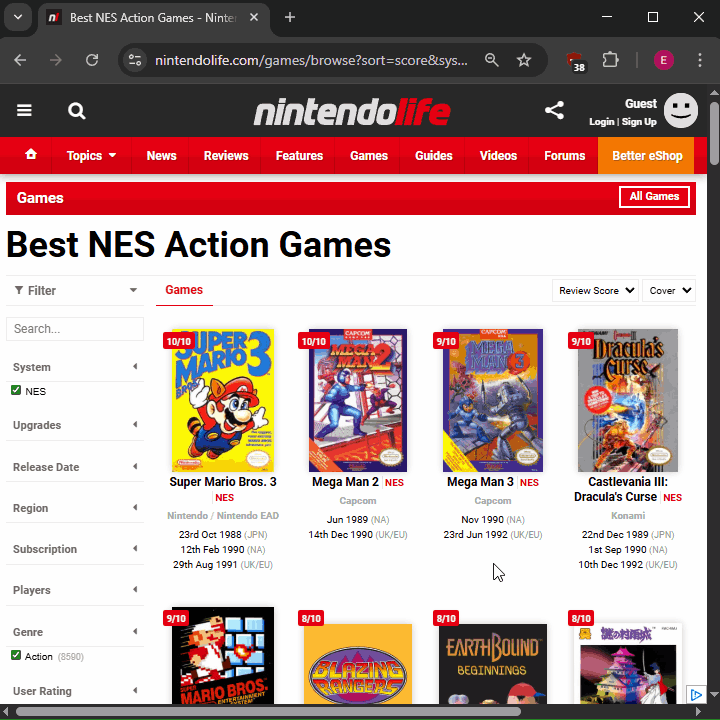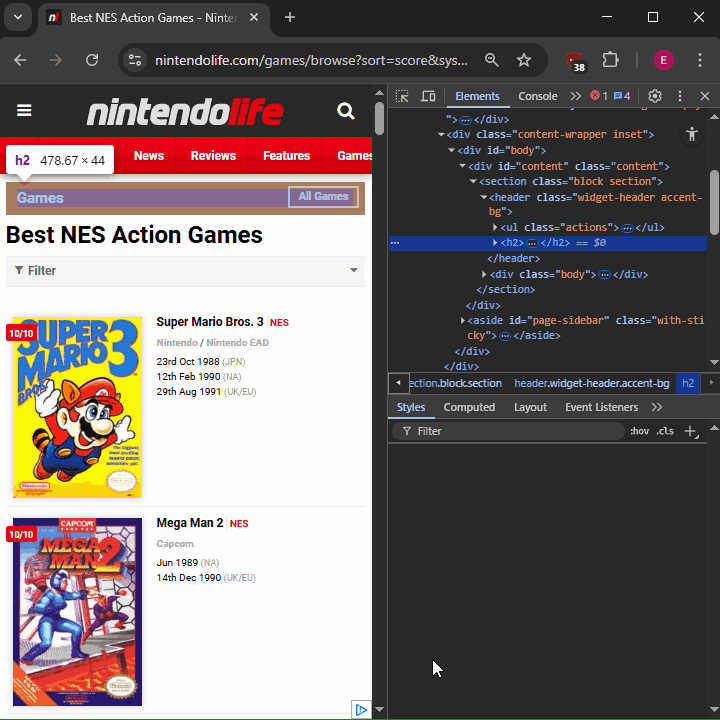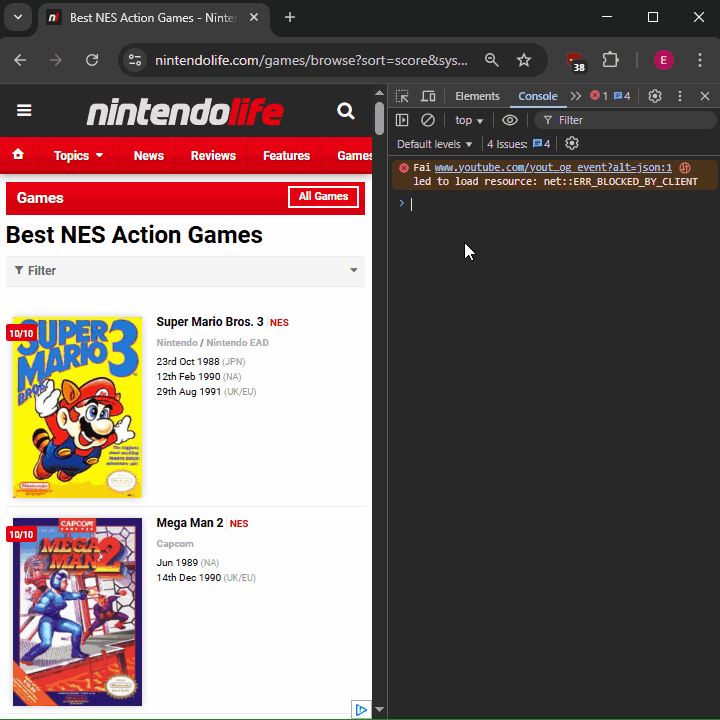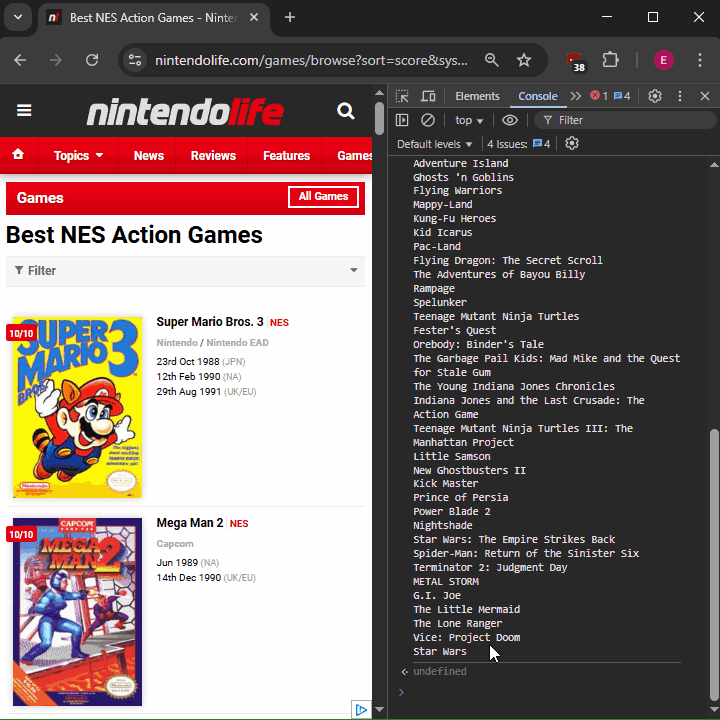
console.log(txt)
1. Guarda en la variable span todos los elementos que coincidan con el Selector especificado, en este caso todos los Elementos "span" que tengan la Clase "title" y que estén dentro del Elemento con Id "listing-games"
2. Crea una variable para ir guardando todos los textos de manera legible
3. Un bucle FOR OF que sirve para recorrer cada elemento de la lista de elementos de la línea 1, recoge el contenido de texto del elemento dado y lo guarda en "txt" junto a un salto de línea
4. Imprime el contenido de la variable "txt"
Para entender todo lo anterior requieres javascript + HTML DOM, otra forma más fácil sería usar un programa especializado en extracción de datos muy amigable, por ejemplo PowerBI, las nuevas versiones son horrendamente pesadas y obviamente no serán compatibles con Windows 7, si mal no recuerdo las nuevas versiones de Excel también pueden extraer datos de páginas web pero me parece que tampoco está a tu disposición XD.
Pienso que una versión viejita de PowerBI que justo acabo de probar en un Windows 7 virtual te puede servir, espero que tengas tu Windows 7 actualizado o PowerBI te va a dar problemas, aunque te avisa si falta algo o puedes comentar por acá si manda algún error
Si te pide Internet Explorer 9 mejor instalas el 11, porque yo grabé el video con el 9 y no se ve muy bonita la interfaz, luego probé con el 11 y si se ve mejor, me refiero a esto:
cin tal cual ignora los espacios, tabulaciones y saltos de línea (Enter) al inicio de lo que se escribe, es decir, si no pones nada y das Enter no pasa nada porque lo ignora, si quieres que no sea ignorado debes usar otra instrucción
Entiendo que estás iniciándote en esto, yo recomiendo siempre un buen libro que detalle el comportamiento de las instrucciones que se usan para entenderlas, por ejemplo:
Revisa la parte de "Entrada y Salida de Datos Básica" ahí lo explica todo, en especial la subparte de "Entrada de Datos"
Normalmente se suele utilizar getline para tomar toda la entrada de datos quitando el Enter final, esto lo puedes ver también en el libro en la sección: "6.2.1. Entrada y Salida de Cadenas de Caracteres"
Para tu ejercicio usando getline sería así:
Código
#include <iostream>
#include <string>
usingnamespace std;
int main (){
struct datos {
string nombre;
int edad;
};
datos persona;
//Pide un nombre, y rechaza la opcion cuando se ingresa "p".
//En vez de "p" debería ingresar un espacio vacío o nada.
do{
cout<<"Ingrese nombre: ";
getline(cin, persona.nombre);
if(persona.nombre.compare("")==0){
cout<<"No hay nombre."<< endl;
}
}while(persona.nombre.compare("")==0);
return0;
}
Recomiendo leer al completo las dos partes que mencioné porque además de mostrar con ejemplos el uso y comportamiento de cada instrucción también muestra posibles errores del uso de estos o la combinación de estos y como solucionarlos. Esto lo digo porque veo que también vas a pedir la Edad que seguramente lo pedirás con cin, en la página 58 y 59 tienes lo que sería tu ejercicio resuelto usando getline y cin con nombre y edad
Me dijeron una forma más sencilla de hacerlo, básicamente: =JERARQUIA.EQV(Q124;$Q$124:$Q$138;0)+CONTAR.SI($Q$124:Q124;Q124)-1
JERARQUIA.EQV genera una lista ordenada de mayor a menor (si pones el argumento 0) y te da la posición (en la lista) del valor que le digas: =JERARQUIA.EQV(valor a buscar;rango en donde buscar;modo)
JERARQUIA.EQV es de las "nuevas" fórmulas que ponen para intentar ser más legibles, como desventaja es que solo funciona con valores numéricos, la fórmula madre CONTAR.SI hace exactamente lo mismo con más lógica, estas dos formulas son completamente equivalentes, aparte de que CONTAR.SI funciona con números y texto:
A B C +----------------------------- 1| JERARQUIA.EQV CONTAR.SI 2| 9 1 1 3| 9 1 1 4| 9 1 1 5| 8 4 4
=JERARQUIA.EQV(A2;$A$2:$A$5;0)
=CONTAR.SI($A$2:$A$5;">"&A2)+1
Citar
Luego se le suma las repeticiones que se encuentren hasta la fila en cuestión, restando 1 para que su propio valor no se cuenta. Eso hace que los valores repetidos más abajo tengan más repeticiones que los mismos de arriba, haciendo que el resultado sea mayor.
Pero acabo de notar un posible error... si un valor tiene muchos repetidos le suma mucho y entonces puede que quede con una posición mayor a la que debe, pero por lo que veo eso no ocurre, no sé por qué
No hay error porque está usando rangos dinámicos CONTAR.SI($Q$124:Q124;Q124), ves que $Q$124 inmoviliza esa coordenada, pero Q124 no está inmovilizado, por eso al arrastrar la fórmula $Q$124 se mantendrá mientras que Q124 se irá incrementando por cada celda que se arrastre aumentando el rango dinámicamente, el último Q124 es la condición, es decir, cuenta cuantas apariciones del valor último (Q124) hay en el rango dinámico $Q$124:Q124
--- Otra opción por la que podrías optar es usar Macros, siempre hay gente purista que lo quiere hacer todo con fórmulas madre, otros con fórmulas matriciales, otros todo con tablas dinámicas, otros todo con macros, etc, es una locura XD, pero es bueno conocer un poco de todo.
Con darle click derecho al nombre de la hoja, Ver código abres el editor de macros, arriba tienes el ámbito (General y Worksheet), se elige Worksheet que corresponde a la Hoja actual, luego se elige el evento, se utilizará Change porque este se ejecuta cada vez que hay cambios en alguna celda de la hoja
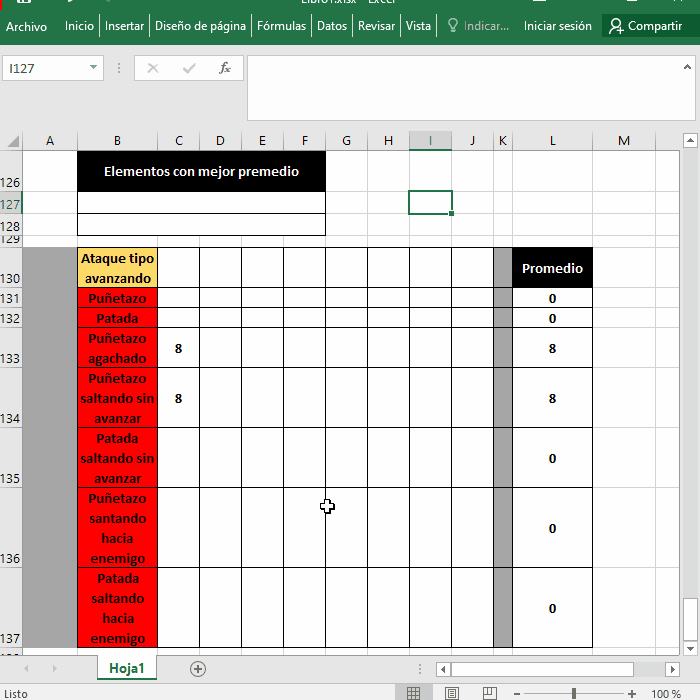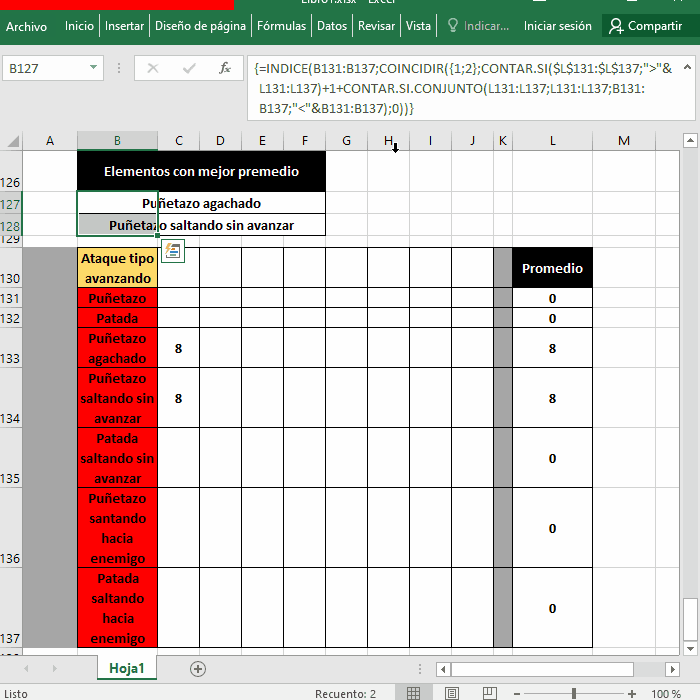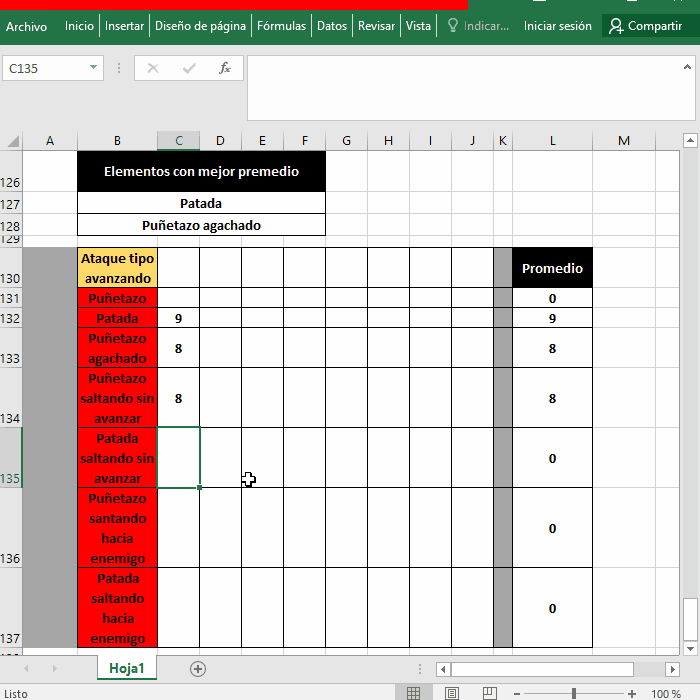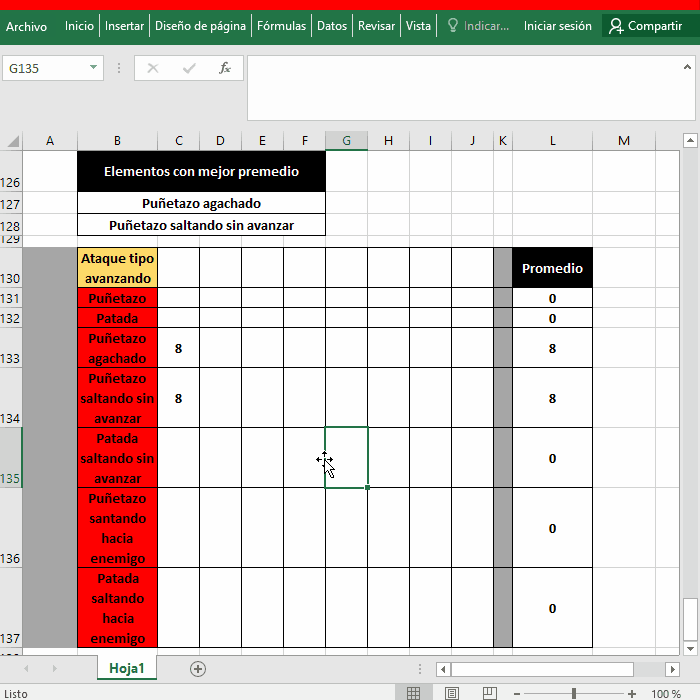
El código es:
Código
PrivateSub Worksheet_Change(ByVal Target As Range)
Application.EnableEvents = False
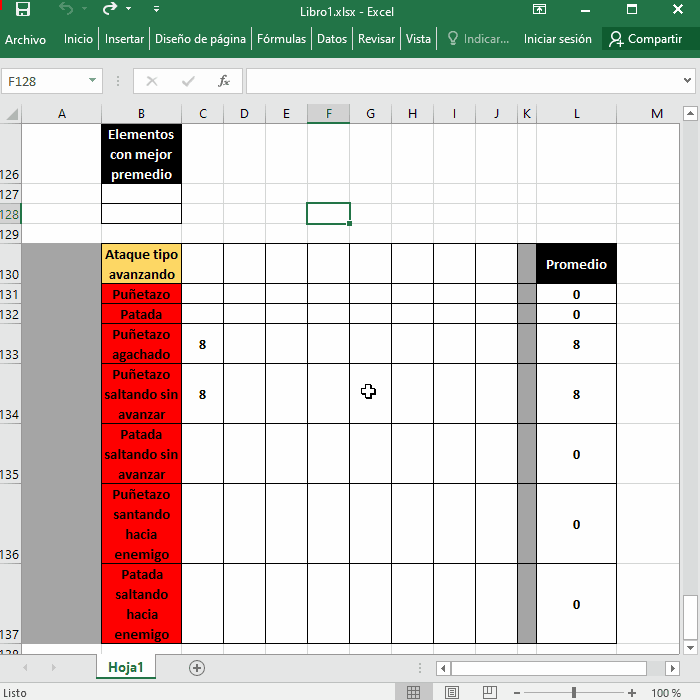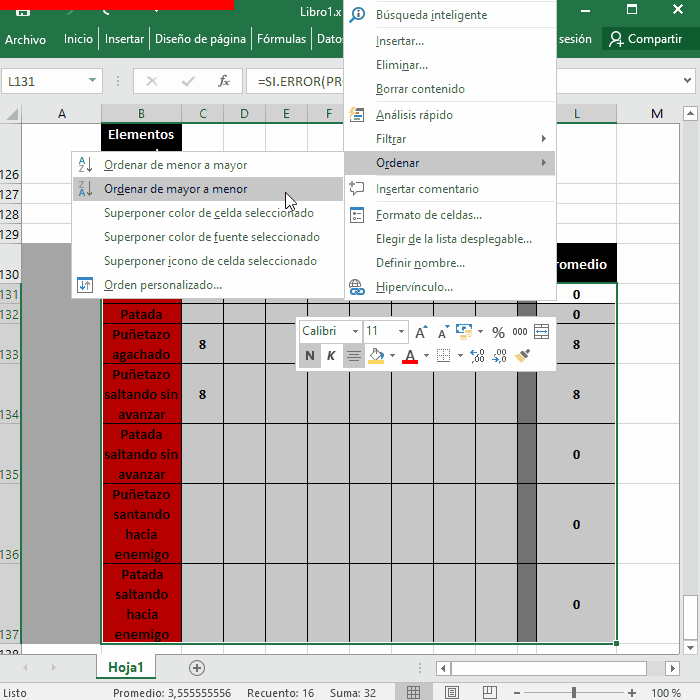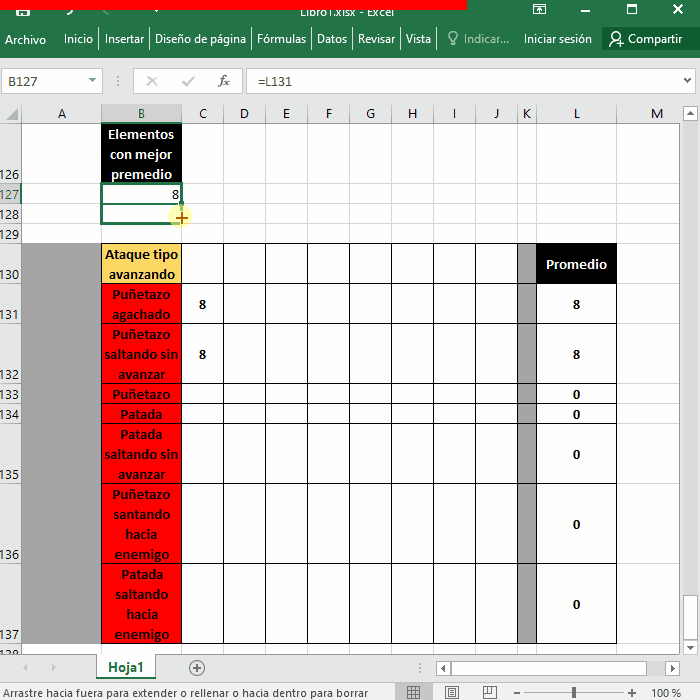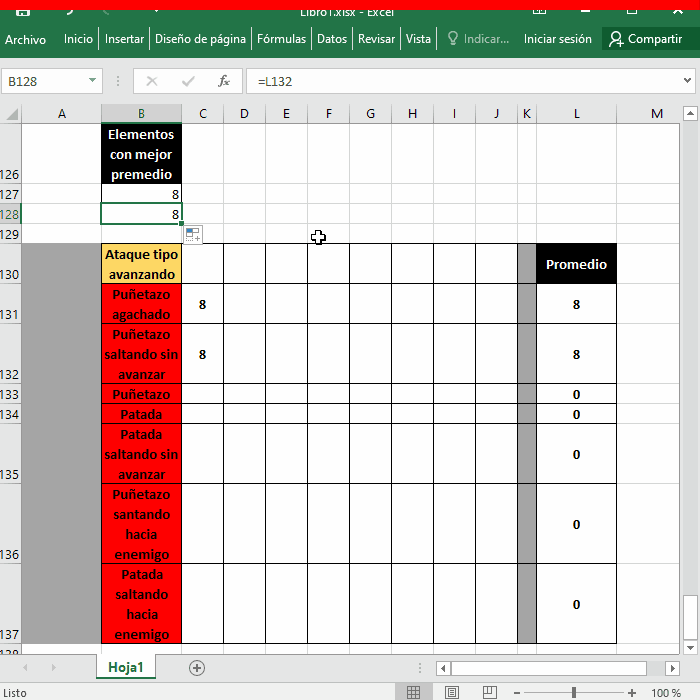
promedios = Range("L131:L137").Value
ataqueTipos = Range("B131:B137").Value
For i = 2 ToUBound(promedios)
For j = 1 ToUBound(promedios) + 1 - i
If promedios(j, 1) < promedios(j + 1, 1) Then
tmp = promedios(j, 1)
promedios(j, 1) = promedios(j + 1, 1)
promedios(j + 1, 1) = tmp
tmp = ataqueTipos(j, 1)
ataqueTipos(j, 1) = ataqueTipos(j + 1, 1)
ataqueTipos(j + 1, 1) = tmp
EndIf
Next
Next
Range("B127") = ataqueTipos(1, 1)
Range("B128") = ataqueTipos(2, 1)
Application.EnableEvents = True
EndSub
1. Indica el tipo de estructura (Private Sub) en este caso es una Procedimiento (función que no devuelve valor), el nombre es Worksheet_Change (puede ser cualquiera, pero el nombre por defecto ya es bastante claro al dar a entender que corresponde al evento Change de la Hoja), luego están los argumentos del Procedimiento, por defecto está el argumento de nombre Target de tipo (As) Range (rango de celdas) y se pasa por valor (ByVal)
2. Esta línea desactiva los eventos, claro, sino cualquier cambio en el Excel volvería a llamar a este Procedimiento, incluso este Procedimiento puede hacer cambios y no queremos que se re-llame, al menos no hasta terminar
3 y 4. Declaro dos variables Array, el primero para guardar los "promedios", y el otro para guardar los "ataques tipos", los Range siempre devuelven Arrays bidimensionales (Fila, Columna), además estos Arrays empezarán con índice 1 en lugar de 0
5 al 16. Es el famoso algoritmo de ordenación Burbuja, los bucles en las Macros de Excel (VBA) tienen diferente sintaxis a las que ya conoces, For inicializar_variable To valor_maximo_de_variable, por ejemplo el clásico for (i = 0; i < 10; i++) en VBA es: For i = 0 To 9, no requiere el i++ porque se sobreentiende que la variable debe aumentar de uno en uno con cada iteración
Ubound devuelve el último índice de un Array, si el Array es: vocales = ("a", "e", "i", "o", "u"), UBound(vocales) devolverá 4 porque se sobreentiende que el array vocales empieza con índice 0:
Ah, y los Arrays en VBA usan paréntesis en lugar de corchetes como se puede ver. Considerando que Range devuelve un Array bidimensional y que además el primer índice empieza en 1, sería algo así suponiendo que las vocales están en el rango "A1:A5" :
Recuerda: vocales(fila, columna), si usas UBound(vocales) devuelve el último índice del array, es decir 5
El Algoritmo de Ordenación es muy popular así que no lo explicaré, salvo las líneas 11, 12 y 13 porque lo que hacen es replicar esa misma ordenación con el Array "ataqueTipos" para replicar esa ordenación, también decir que en todos los casos se está índicando el 1 en por ejemplo promedio(j,1) porque el Array es bidimensional pero como solo tiene una Columna y no necesitamos más, ponemos 1, solo varía la Fila
17 y 18 Escriben el primer y segundo valor del Array ordenado en la celda de resultados
19 Vuelve a activar los eventos
--- Adjunto el archivo de excel para que lo revises, y otra cosa importante de las Macros es que para que se conserven debes guardar el archivo como .xlsm en lugar de .xlsx, el propio excel te lo recordará, aparte de los permisos y confianza en las macros claro, esa es la desventaja de las macros, muy escandalosas
Debo crear columnas al lado de esa, y es muy tedioso cambiar las letras. A y B deben mantenerse, pero si le pongo los $ no van a cambiar los números cuando quiera que lo hagan hacia abajo. Y N debe cambiar a M, luego a O, etc, pero si no le pongo los $ aumentarían los números de los rangos cuando quiera que la fórmula se aplique más abajo.
Si A y B deben mantenerse ponles un $ delante: $A $B, ambos son indicadores de columnas, si arrastras verticalmente nunca cambiarán, si arrastras horizontalmente si cambiaran salvo que tengan los $ delante, los números son indicadores de filas, de forma similar nunca cambiaran si arrastras horizontalmente, pero si cambiaran si arrastras verticalmente salvo que tengan el $ delante
Citar
A y B deben mantenerse, pero si le pongo los $ no van a cambiar los números cuando quiera que lo hagan hacia abajo.
Y N debe cambiar a M, luego a O, etc, pero si no le pongo los $ aumentarían los números de los rangos cuando quiera que la fórmula se aplique más abajo.
N solo cambiará a M si arrastras horizontalmente hacia la izquierda y solo si le quitas los $, pero que luego M cambie a O?, eso ya está raro, supongo que te equivocaste
Recuerda que puedes presionar el atajo de teclado F4 para que la fijación ($) vaya cambiando entre: Fijar todo ($A$1), solo Columna ($A1), solo Fila (A$1) o nada (A1), obviamente tienes que tener el cursor en el A1 o seleccionarlo, también te vale para Rangos (A1:A5)
Esas cosas siempre tienen un grado de complejidad si lo quieres hacer con fórmulas, y está bien para quienes dominan las formulas madre de Excel y/o trabajan con datos que cambian constantemente en vivo. PERO no creo que sea tu caso SALVO quieras aprender y profundizar en el uso de fórmulas y matrices.
Lo normal y que cualquiera puede hacer es ordenar los datos con la herramienta Ordenar, tanto mejor si tu "tabla de datos" es una Tabla porque ya tiene los botones de Ordenar y Filtrar, en tu imagen de arriba solo resta poner =L131 y =L132 respectivamente:
Sin Tabla (empezar la selección desde la celda o columna que será la base de la ordenación):
Con Tabla:
Desventajas:
- No son automáticas, debes asegurarte de volver a Ordenar luego de ingresar/cambiar los datos - Modifican el orden original de tus datos, dependerá si te importa o no cambiar el orden perdiendo el orden original
Ventajas:
- Es facilísimo
---
Ahora bien, si lo quieres hacer con fórmulas hay pasos que tienes que seguir y dominar:
1. Obtener el número de orden que ocupa un valor dentro de un rango de valores ordenados, en tu caso de mayor a menor. La forma convencional de hacer esto es tomar un valor dentro de un rango de valores y contar la cantidad de valores que son mayores, si dicha cantidad es 0 implica que estamos ante el valor mayor, si la cantidad es 1 será el segundo mayor, y así sucesivamente. Entonces, si le sumamos a esa cantidad: +1 obtendremos su número de orden, porque si la cantidad fue 0 implica que es el primer lugar, si la cantidad fue 1 implica que es el segundo lugar, etc
2. Valores repetidos, si es el caso hay que decidir que orden tendrán los valores repetidos, por lo general se suele usar una condición adicional que actúe sobre otra columna, por ejemplo si fuera una tabla de nombres y apellidos, y se desea ordenar por los nombres:
carlos | lópez maría | tórres carlos | flores
- Tenemos problemas con el nombre "carlos" ya que se repite, Si hiciéramos el paso 1 obtendríamos:
carlos | lópez | 1 maría | tórres | 3 carlos | flores | 1
- La solución está en hacer una condición adicional para comprobar el orden de los apellidos dándoles valores igual que en el paso 1 pero sin sumarles el +1, y al final contar/sumar ambos números de orden para obtener un número de orden sin repeticiones
carlos | lópez | 2 maría | tórres | 3 carlos | flores | 1
- Para tu caso puedes comprobar el orden de los valores de la columna "ataque tipo avanzado" correspondiente a los valores repetidos, justo como se hizo con el ejemplo de nombres y apellidos
- Su funcionamiento es sencillo, solo hay que despejar los valores repetidos y al resultante asignarle un número de orden, esta vez no sumaremos el +1 para que empiece en 0, al final se suma ese orden obtenido al número de orden del paso 1:
-- Despejado
carlos | lópez carlos | flores
-- Número de orden con respecto al apellido
carlos | lópez | 1 carlos | flores | 0
-- Sumado al número de orden del paso 1:
carlos | lópez | 1 + 1 carlos | flores | 0 + 1
-- De esa manera "carlos flores" queda en primer lugar (1) y "carlos lópez" en segundo (2)
3. Localizar el valor de la columna requerida a partir de lo calculado anteriormente, en los pasos anteriores se obtiene el número de orden para cada fila, ya solo falta obtener que número de fila tiene el número de orden 1 y 2
carlos | lópez | 2 maría | tórres | 3 carlos | flores | 1
- Tan simple como decirle que primero quiero el valor de la columna de apellidos cuyo número de orden es 1, y luego quiero el valor de la columna apellidos cuyo número de orden es 2. Listo, esos serán los 2 primeros apellidos ordenados por nombres de forma ascendente.
carlos | flores | 1 carlos | lópez | 2
---
Resolución:
Paso 1: Basta con usar una columna auxiliar, por ejemplo la que está al lado (M131) y aplicar la función =CONTAR.SI($L$131:$L$137;">"&L132)+1
Paso 2: Como hay valores repetidos modificamos la fórmula con la segunda condición:
- Con CONTAR.SI.CONJUNTO se pueden hacer varias condiciones que van reduciendo el rango de datos para la subsiguiente condición, lo primero era despejar los repetidos, eso se hace con la parte en rojo:
- Una vez despejado/marcado los repetidos aplicamos la condición: $B$131:$B$137;"<"&B132 que similar al paso 1 ordenará los valores de la columna "ataque tipo avanzado" pero esta vez de menor a mayor (a-z), todo esto considerando el despeje anterior, es decir, solo las filas correspondientes a los repetidos, de esta manera se obtiene un segundo orden que se puede sumar al CONTAR.SI inicial y tener un orden secuencial sin repeticiones SALVO que también haya repeticiones en la columna de la segunda condición XD, si es el caso hay que agregar más condiciones con más columnas o especificar una condición personal.
Paso 3: Primero hay que localizar el número de fila dentro de un rango que tiene el número de orden 1 (el valor mayor), esto se hace con la fórmula COINCIDIR, una vez obtenido el número de fila solo queda obtener el valor de la columna "ataque tipo avanzado" con la fila hallada con COINCIDIR, esto se hace con INDICE, lo mismo para el número de orden 2 (segundo mayor) todo sería:
- Pues ya está, esto todo SI vas a usar la columna auxiliar que se ha creado en M131, pero si no quieres columna auxiliar se tiene que juntar todo, usar matrices donde las fórmulas esperan valores simples y obviamente presionar Ctrl + Shift + Enter para que haga valer las matrices que se han puesto en lugar de los valores simples, en resumen:
- Como ves, se han reemplazado todas las referencias a valores simples por rangos para que trabaje de manera matricial, incluso se ha reemplazado el número 1 o 2 que antes se usaba en dos fórmulas aparte, por una matriz manual de tal manera que el resultado a devolver también sea una matriz de dos filas que son justo las filas que hay que seleccionar para poner el resultado en ellas.
- Si no se conoce bien las matrices no se va a entender XD, pero puedo dar una explicación sencilla con la parte de CONTAR.SI(L131:L137;">"&L131:L137) que supongo que es una parte fácil de entender.
-- La función CONTAR.SI(rango;condición) tiene una par de argumentos base, primero un rango y luego la condición, dicha condición que se espera de valor simple, sin embargo yo le he puesto una condición de rango, por haber hecho esto ya se convierte en una fórmula matricial al que se tiene que presionar Ctrl + Shift + Enter y que además devuelve la matriz resultante.
-- Lo normal sería que dicha función tome un rango y una condición, lo que hará es tomar uno a uno los valores del rango, compararlos usando la condición y si se cumple cuenta +1:
CONTAR.SI(A1:A3;"<"&A1)
carlos | lópez | 0 maría | tórres | 2 carlos | flores | 0
1. Toma el primer miembro del rango (A1) y compara si es menor que A1, si es menor +1, sino 0 2. Toma el segundo miembro del rango (A2) y compara si es menor que A1, si es menor +1, sino 0 3. Toma el tercer miembro del rango (A3) y compara si es menor que A1, si es menor +1, sino 0
En los casos anteriores da 0;0;0 se cuentan y da 0, ahora la siguiente:
CONTAR.SI(A1:A3;"<"&A2)
1. Toma el primer miembro del rango (A1) y compara si es menor que A2, si es menor +1, sino 0 2. Toma el segundo miembro del rango (A2) y compara si es menor que A2, si es menor +1, sino 0 3. Toma el tercer miembro del rango (A3) y compara si es menor que A2, si es menor +1, sino 0
En los casos anteriores da 1;0;1 se cuentan y da 2
Como se ve se tiene que poner una fórmula por fila, es como hacer un bucle simple:
=CONTAR.SI(A1:A3;"<"&A1)
Código
rango =["carlos","maría","carlos"]
valor = rango[0]//"carlos"
contar1 =0
for(var i =0; i < rango.length; i++){
if(rango[i]< valor){
contar1++
}
}
valor = rango[1]//"maría"
contar2 =0
for(var i =0; i < rango.length; i++){
if(rango[i]< valor){
contar2++
}
}
valor = rango[2]//"carlos"
contar3 =0
for(var i =0; i < rango.length; i++){
if(rango[i]< valor){
contar3++
}
}
Devuelve un solo valor cada uno (contar1, contar2, contar3) y la comparación es simple, rango vs valor, y hay que hacer lo mismo con cada valor. Al final devuelve contar1 = 0; contar2 = 2; contar 3 = 0
Pero si usamos otro rango en lugar del valor simple (A1 => A1:A3):
CONTAR.SI(A1:A3;"<"&A1:A3)
Código
rango1 =["carlos","maría","carlos"]
rango2 =["carlos","maría","carlos"]
contar =[0,0,0]
for(var i =0; i < rango1.length; i++){
for(var j =0; j < rango2.length; j++){
if(rango1[j]< rango2[i]){
contar[i]++
}
}
}
Devuelve un array contar = [0,2,0], más simple, más directo PERO devuelve una matriz de valores que se deben tratar como tales
---
Otra opción es utilizar las nuevas fórmulas de filtro dinámicas que trae las nuevas versiones de Excel, creo que del 2021 para arriba
El resultado por Flamer es correcto, justo esos operadores son para trabajar con números muy grandes pero obviamente no son compatibles con el viejo Flash5, sale lo mismo con SpeedCrunch que es el que yo recomendé. Masterplc seguramente está redondeando, habrá que ver cuantos dígitos soporta, pero normalmente si no lo dicen es que son pocos. Y el de GPT pues está muy mal, tendrás que pedirle que te explique que algoritmo utilizó o la precisión del resultado que te da.
Como dije, el convertir no te sirve porque igual vas a operar números grandes que están fuera del alcance de Flash, sí puedes convertir para intentar entender al utilizar la conocida base 10. El detalle está en las operaciones, lo que le tienes que pedir a ChatGPT es que te de una función para Operar números como string, has mencionado que necesitas División y Resta.
Estas operaciones de División y Resta podrían ser los de toda la vida, de esas que haces con lápiz y papel, directamente puedes hacer esas operaciones en cualquier Base, en tu caso Binario me parece, por ejemplo (123456789 / 123):
Como puedes ver el número más grande que se toma será más o menos igual al divisor, si el divisor no es tan grande puedes operar sin problemas, pero si no es el caso tendrás que usar algoritmos más complejos como ese que te mandó ChatGPT, y entenderlos es complejo, primero tendrías que ver que algoritmo está utilizando, una descripción general de los pasos al menos, y dedicarle varias horas en entenderlo
Por el vistazo rápido que le di, me parece que está haciendo la inversa de conversión de Decimal a Binario usando el algoritmo de sucesivas divisiones entre 2, además está guardando cada dígito del resultante en un array teniendo cuidado de que si dicho dígito no supere el 9, si es así lo "lleva" para sumarlo al siguiente dígito.
Por ejemplo:
Convertir 13 a binario, se hacen divisiones sucesivas entre 2, al final se recolectan desde el último cociente y los residuos en ese orden para obtener el binario
13 / 2 1 6 / 2 0 3 / 2 1 1 => 1101
Para hacer lo inverso se aplica la fórmula de Dividendo = (Cociente * Divisor) + residuo, y se va haciendo lo mismo hasta utilizar todos los dígitos binarios y así obtener el primer Dividendo que será el número Decimal original
En Flash 5 el número entero más grande con el que puedes trabajar es 9007199254740992 (2^53) en en algún momento operas superando ese valor se usarán aproximaciones que obviamente perderán precisión dependiendo cuan alejados estén al límite de 2^53.
Convertir no te sirve porque igual vas a llegar a superar ese valor al intentar realizar alguna operación. Las soluciones que tienes es buscar otra forma dependiendo de como funcione tu programa o lo que quieras lograr, o trabajar todo sin convertirlo completamente, por ejemplo si intentas convertir de binario_string a decimal se te complica porque debes hacer operaciones con números enormes al depender de operaciones que involucran cada caracter
En caso de convertir de binario_string a hexadecimal lo tienes muy sencillo porque tomas de 4 en 4 bits y los conviertes a hexadecimal concatenando todo y ya está, no es necesario trabajar con todos los caracteres ni operar con todos ellos a la vez PERO el problema viene cuando dices: luego debo dividir entre otro número, ahí se rompe todo porque lo tendrás que convertir a número, lo que podrías hacer es crear una función propia para hacer la división, ya sea trabajando todo en binario, o hexadecimal, o decimal (pidiéndole a ChatGPT una función rarísima que ni se entienda XD).
Pues si por ejemplo trabajas en binario_string puro y quieres dividir lo haces como se haría con papel y lápiz a mano (como en el colegio), si el trabajo lo va hacer ChatGPT pues mejor le pides que lo trabaje todo así sin hacer conversiones innecesarias, que cree una función que divida dos binario_string
Ahora bien, con respecto a las calculadoras, la de Windows obviamente no está preparada para esas locuras XD, aunque está el viejo Microsoft Mathematics que no tendría problemas pero es una aplicación más avanzadita, para hacer tus pruebas sin errores yo te recomendaría SpeedCrunch https://heldercorreia.bitbucket.io/speedcrunch/download.html si deseas puedes bajar la versión instalable o la portable, es muy amigable para los programadores porque es sencillísima, una forma de poner a prueba la calculadora es operando, esta calculadora puede trabajar con números de hasta 78 dígitos sin perder precisión, Excel por otro lado solo puede con 15 dígitos. Por ejemplo con SpeedCrunch:
Mira que puse el 0b delante, eso es para especificar que estás usando un binario tal cual es 0x para los hexadecimales. Con darle un Enter te devuelve en ese número en Decimal:
18374403900871474688
Servirá como referencia, ahora hago la siguiente operación:
Como resultado me muestra: 2268444905390666566675256832
Ahora el resultado de la operación anterior lo divido entre 123456789 para ver si obtengo el mismo número de la referencia:
2268444905390666566675256832 / 123456789
Devuelve: 18374403900871474688 que es exactamente igual a la muestra, es más lo puedo convertir a binario con:
bin(18374403900871474688)
dando: 0b1111111011111110111111101111111011111110111111101111111000000000 que es exactamente el binario original, es decir, no pierdes nada de precisión
Primero debes haber cumplido la indicación 2 del readme.txt de "C:\borland\bcc55\readme.txt"
Citar
2. From the bin directory of your installation: a. Add "c:\Borland\Bcc55" to the existing path b. Create a bcc32.cfg file which will set the compiler options for the Include and Lib paths (-I and -L switches to compiler) by adding these lines: -I"c:\Borland\Bcc55\include" -L"c:\Borland\Bcc55\lib" c. Create an ilink32.cfg file which will set the linker option for the Lib path by adding this line: -L"c:\Borland\Bcc55\lib"
Tengo entendido que el paso "a" ya lo hiciste, aunque lo que se tiene que agregar al PATH es C:\borland\bcc55\bin , el paso "b" pide crear el archivo "C:\borland\bcc55\bcc32.cfg" con contenido:
Ahora toca abrir Geany (cerrar y volver a abrir si ya lo tenias abierto), ir al menú "Construir" > "Establecer comandos de construcción", solo hay que cambiar el primer cuadrito que dice: gcc -wall -c "%f" por: bcc32 "%f", das en Aceptar y ya está.
Para compilar tu código te vas al menú Construir > Compile (F8), y para ejecutarlo vas a Construir > Execute (F5). Necesitas hacer ambos pasos para ver los resultados.