Autor Autor
|
Tema: Buscador de combinaciones inexistentes no funciona. (Leído 7,145 veces)
|
Tachikomaia
 Desconectado Desconectado
Mensajes: 1.610
Hackentifiko!

|
Relacionado con: https://foro.elhacker.net/hacking/descartar_combinaciones_de_caracteres_al_buscar_password-t522886.0.htmlCódigo dado por GPT: import itertools def cargar_diccionario(ruta): """Carga el diccionario desde un archivo .txt y devuelve un conjunto de palabras en minúsculas.""" with open(ruta, 'r', encoding='utf-8') as archivo: return set(palabra.strip().lower() for palabra in archivo) def generar_combinaciones(alfabeto): """Genera todas las combinaciones posibles de dos letras del alfabeto.""" return {a + b for a, b in itertools.product(alfabeto, repeat=2)} def buscar_combinaciones(diccionario, combinaciones): """Busca combinaciones dentro de las palabras del diccionario.""" presentes = set() # Buscar combinaciones dentro de palabras individuales for palabra in diccionario: for i in range(len(palabra) - 1): presentes.add(palabra[i:i+2]) # Buscar combinaciones entre palabras consecutivas lista_palabras = sorted(diccionario) # Ordenar las palabras for i in range(len(lista_palabras) - 1): ultima_letra = lista_palabras[-1] primera_letra = lista_palabras[i + 1][0] presentes.add(ultima_letra + primera_letra) return combinaciones - presentes # Paso 1: Cargar diccionarios diccionario_es = cargar_diccionario('diccionario_es.txt') diccionario_en = cargar_diccionario('diccionario_en.txt') # Paso 2: Generar combinaciones posibles alfabeto_es = 'abcdefghijklmnñopqrstuvwxyz' alfabeto_en = 'abcdefghijklmnopqrstuvwxyz' combinaciones_es = generar_combinaciones(alfabeto_es) combinaciones_en = generar_combinaciones(alfabeto_en) # Paso 3: Buscar combinaciones inexistentes en cada diccionario inexistentes_es = buscar_combinaciones(diccionario_es, combinaciones_es) inexistentes_en = buscar_combinaciones(diccionario_en, combinaciones_en) # Paso 4: Combinar resultados y mostrar combinaciones inexistentes en ambos idiomas inexistentes_totales = inexistentes_es.intersection(inexistentes_en) print(f"Combinaciones inexistentes en ambos idiomas ({len(inexistentes_totales)}):") print(sorted(inexistentes_totales))
Tengo los diccionarios y les puse los nombres que dice ahí: diccionario_es.txt diccionario_en.txt El programa se cierra enseguida sin que yo pueda ver qué pasa. ¿Cual es la falla, cómo lo arreglo?
|
|
|
|
|
 En línea
En línea
|
|
|
|
|
EdePC
|
El programa se cierra enseguida sin que yo pueda ver qué pasa. ¿Cual es la falla, cómo lo arreglo? O_o? Es un aplicación/script de consola o línea de comando (como john the ripper), usa una consola (CMD, Símbolo del Sistema, PowerShell, etc), también puedes poner una "pausa" antes de que se cierre pero si hay errores no los mostrará a no ser que lo ejecutes en una consola que es como debe de ser. Para poner la pausa puedes agregar un input al final o donde quieras la pausa: input("Presione Enter para continuar ...")
|
|
|
|
|
En línea
|
|
|
|
Tachikomaia
Desconectado
Mensajes: 1.610
Hackentifiko!
|
Es un archivo py abierto con Python, eso me lo enseñaron aquí, posiblemente tú.
Luego te digo el resultado.
|
|
|
|
|
En línea
|
|
|
|
Tachikomaia
Desconectado
Mensajes: 1.610
Hackentifiko!
|
No cambió el resultado, se cierra enseguida. import itertools def cargar_diccionario(ruta): """Carga el diccionario desde un archivo .txt y devuelve un conjunto de palabras en minúsculas.""" with open(ruta, 'r', encoding='utf-8') as archivo: return set(palabra.strip().lower() for palabra in archivo) def generar_combinaciones(alfabeto): """Genera todas las combinaciones posibles de dos letras del alfabeto.""" return {a + b for a, b in itertools.product(alfabeto, repeat=2)} def buscar_combinaciones(diccionario, combinaciones): """Busca combinaciones dentro de las palabras del diccionario.""" presentes = set() # Buscar combinaciones dentro de palabras individuales for palabra in diccionario: for i in range(len(palabra) - 1): presentes.add(palabra[i:i+2]) # Buscar combinaciones entre palabras consecutivas lista_palabras = sorted(diccionario) # Ordenar las palabras for i in range(len(lista_palabras) - 1): ultima_letra = lista_palabras[-1] primera_letra = lista_palabras[i + 1][0] presentes.add(ultima_letra + primera_letra) return combinaciones - presentes # Paso 1: Cargar diccionarios diccionario_es = cargar_diccionario('diccionario_es.txt') diccionario_en = cargar_diccionario('diccionario_en.txt') # Paso 2: Generar combinaciones posibles alfabeto_es = 'abcdefghijklmnñopqrstuvwxyz' alfabeto_en = 'abcdefghijklmnopqrstuvwxyz' combinaciones_es = generar_combinaciones(alfabeto_es) combinaciones_en = generar_combinaciones(alfabeto_en) # Paso 3: Buscar combinaciones inexistentes en cada diccionario inexistentes_es = buscar_combinaciones(diccionario_es, combinaciones_es) inexistentes_en = buscar_combinaciones(diccionario_en, combinaciones_en) # Paso 4: Combinar resultados y mostrar combinaciones inexistentes en ambos idiomas inexistentes_totales = inexistentes_es.intersection(inexistentes_en) print(f"Combinaciones inexistentes en ambos idiomas ({len(inexistentes_totales)}):") print(sorted(inexistentes_totales)) input("Presione Enter para continuar ...")
¿Será que requiere una versión más nueva que la que tengo? El problema que describes probablemente no está relacionado con la versión de Python, sino con un **error en tu código** que provoca que el programa termine antes de lo esperado. Vamos a analizarlo detalladamente.
### Posibles problemas en el código
1. **Error en la sección de combinaciones entre palabras consecutivas**:
En el método `buscar_combinaciones`, en esta línea:
```python
ultima_letra = lista_palabras[-1]
primera_letra = lista_palabras[i + 1][0]
presentes.add(ultima_letra + primera_letra)
```
Hay un error de lógica. La variable `ultima_letra` intenta tomar el valor de la última palabra completa de la lista (`lista_palabras[-1]`), pero lo que necesitas es la **última letra de la palabra actual** (`palabra_actual[-1]`). Aquí tienes una corrección:
```python
ultima_letra = lista_palabras[-1] # Última letra de la palabra actual
primera_letra = lista_palabras[i + 1][0] # Primera letra de la siguiente palabra
presentes.add(ultima_letra + primera_letra)
```
2. **Falta de manejo de excepciones en la lectura de los archivos**:
Si los archivos `diccionario_es.txt` o `diccionario_en.txt` no existen, el programa lanzará un error y se cerrará. Asegúrate de manejar este caso con un bloque `try-except` para evitar que el programa termine inesperadamente:
```python
def cargar_diccionario(ruta):
"""Carga el diccionario desde un archivo .txt y devuelve un conjunto de palabras en minúsculas."""
try:
with open(ruta, 'r', encoding='utf-8') as archivo:
return set(palabra.strip().lower() for palabra in archivo)
except FileNotFoundError:
print(f"Error: No se encontró el archivo {ruta}.")
return set()
```
3. **Errores en los datos de entrada**:
Si el archivo de diccionario contiene caracteres especiales, líneas vacías o palabras que no se procesan correctamente, el programa podría comportarse de manera inesperada. Asegúrate de que los archivos de entrada estén en el formato correcto (palabras en minúsculas, una por línea).
4. **El programa finaliza correctamente pero no esperas ese comportamiento**:
Si el programa no tiene errores, la última línea:
```python
input("Presione Enter para continuar ...")
```
debería mantener la ventana abierta hasta que presiones **Enter**. Sin embargo, si estás ejecutándolo desde un entorno donde la ventana se cierra automáticamente al finalizar (por ejemplo, al ejecutar un archivo `.py` en Windows haciendo doble clic), esto puede parecer un cierre inesperado.
Para evitar este problema, te recomiendo ejecutar el programa desde una terminal o consola manualmente con:
```bash
python tu_programa.py
```
Esto asegurará que la ventana no se cierre automáticamente después de la ejecución.
---
### Solución ajustada del código
Aquí está el código corregido con las observaciones mencionadas:
```python
import itertools
def cargar_diccionario(ruta):
"""Carga el diccionario desde un archivo .txt y devuelve un conjunto de palabras en minúsculas."""
try:
with open(ruta, 'r', encoding='utf-8') as archivo:
return set(palabra.strip().lower() for palabra in archivo if palabra.strip())
except FileNotFoundError:
print(f"Error: No se encontró el archivo {ruta}.")
return set()
def generar_combinaciones(alfabeto):
"""Genera todas las combinaciones posibles de dos letras del alfabeto."""
return {a + b for a, b in itertools.product(alfabeto, repeat=2)}
def buscar_combinaciones(diccionario, combinaciones):
"""Busca combinaciones dentro de las palabras del diccionario."""
presentes = set()
# Buscar combinaciones dentro de palabras individuales
for palabra in diccionario:
for i in range(len(palabra) - 1):
presentes.add(palabra[i:i+2])
# Buscar combinaciones entre palabras consecutivas
lista_palabras = sorted(diccionario) # Ordenar las palabras
for i in range(len(lista_palabras) - 1):
ultima_letra = lista_palabras[-1] # Última letra de la palabra actual
primera_letra = lista_palabras[i + 1][0] # Primera letra de la siguiente palabra
presentes.add(ultima_letra + primera_letra)
return combinaciones - presentes
# Paso 1: Cargar diccionarios
diccionario_es = cargar_diccionario('diccionario_es.txt')
diccionario_en = cargar_diccionario('diccionario_en.txt')
# Verificar si los diccionarios se cargaron correctamente
if not diccionario_es or not diccionario_en:
print("No se pudieron cargar los diccionarios. Por favor, verifica los archivos.")
exit()
# Paso 2: Generar combinaciones posibles
alfabeto_es = 'abcdefghijklmnñopqrstuvwxyz'
alfabeto_en = 'abcdefghijklmnopqrstuvwxyz'
combinaciones_es = generar_combinaciones(alfabeto_es)
combinaciones_en = generar_combinaciones(alfabeto_en)
# Paso 3: Buscar combinaciones inexistentes en cada diccionario
inexistentes_es = buscar_combinaciones(diccionario_es, combinaciones_es)
inexistentes_en = buscar_combinaciones(diccionario_en, combinaciones_en)
# Paso 4: Combinar resultados y mostrar combinaciones inexistentes en ambos idiomas
inexistentes_totales = inexistentes_es.intersection(inexistentes_en)
print(f"Combinaciones inexistentes en ambos idiomas ({len(inexistentes_totales)}):")
print(sorted(inexistentes_totales))
input("Presione Enter para continuar ...")
```
---
### Resumen de los cambios
1. **Corrección de la lógica al buscar combinaciones entre palabras consecutivas.**
2. **Manejo de excepciones al cargar los archivos.**
3. **Validación para asegurarte de que los diccionarios se carguen correctamente.**
4. **Sugerencia de ejecutar el programa desde la terminal para evitar que la ventana se cierre automáticamente.**
Con estas correcciones, el programa debería funcionar correctamente si tienes una versión de Python reciente (3.6 o superior).Demasiado lío, el código me lo dió él, si ahora dice que tiene errores mejor empiezo por algo más simple que yo pueda entender. |
|
|
|
« Última modificación: 5 Enero 2025, 13:25 pm por Tachikomaia »
|
En línea
|
|
|
|
|
EdePC
|
Eso es porque no entiendes el código que te manda ChatGPT, y eso agravado en que Python puede llegar a sonar a chino por sus "instrucciones complejamente simplificadas" porque difieren mucho a los de lenguajes de programación más clásicos, debes tener el manual de python a la mano y tratar de entender que hace cada cosa o decirle a ChatGPT que te lo explique, olvida cualquier otro lenguaje de programación clásico como ActionScript o solo formarás contradicciones en tu cabeza. También le puedes decir a ChatGPT que use un lenguaje más clásico y estándar en python para que sea más legible. De todas maneras el script a mi si me funciona, tengo la versión 3.8.10 de Python e incluso un doble click me sirve: 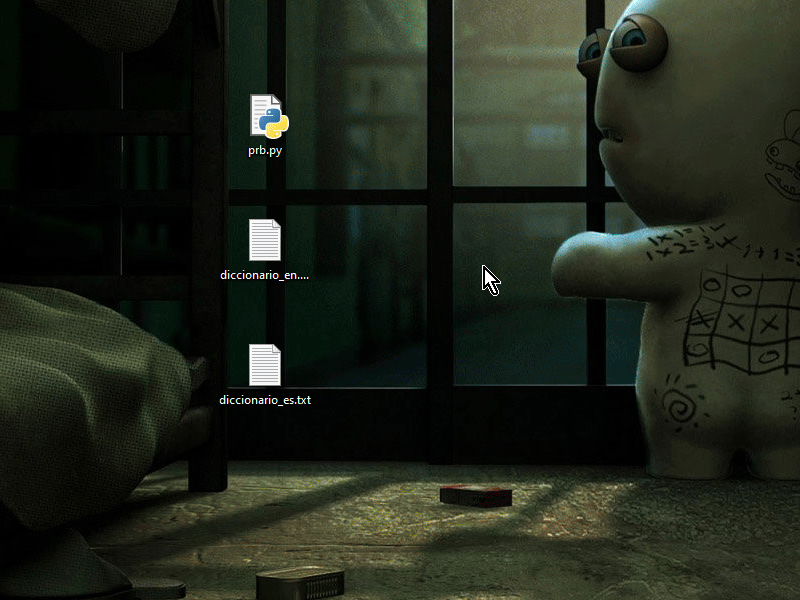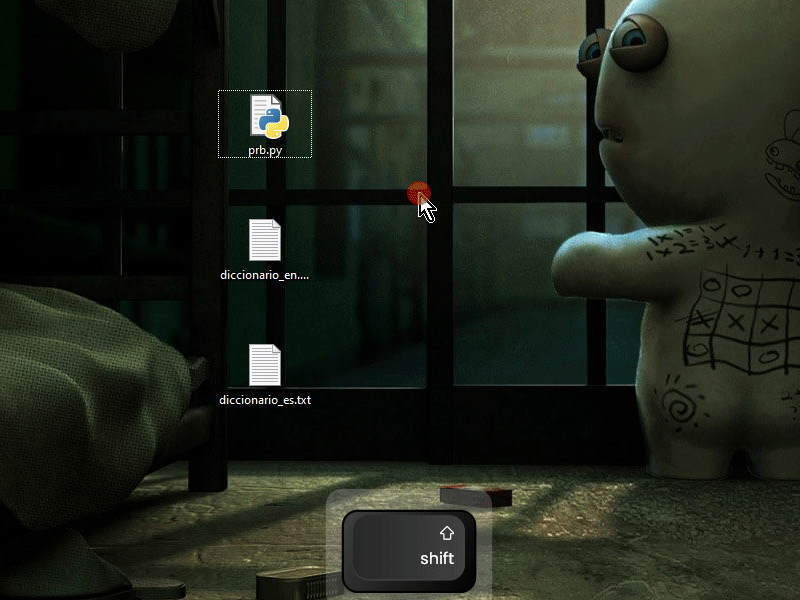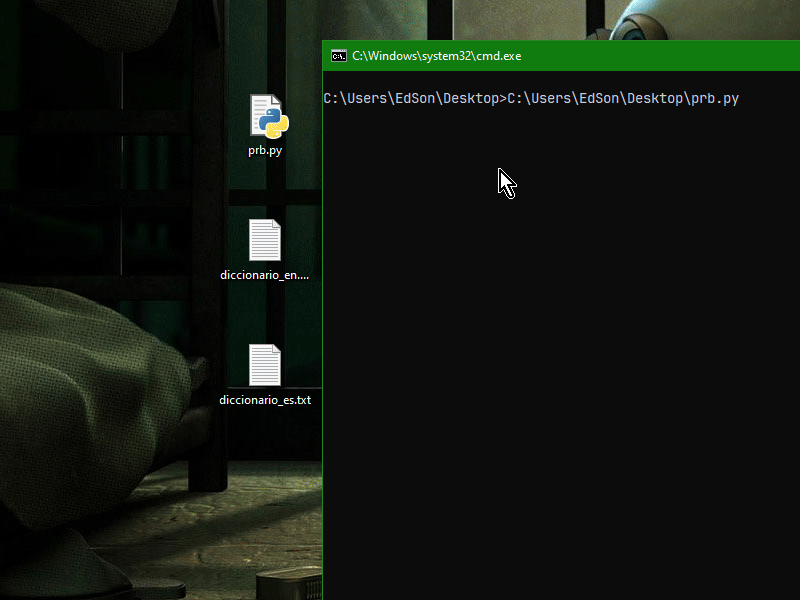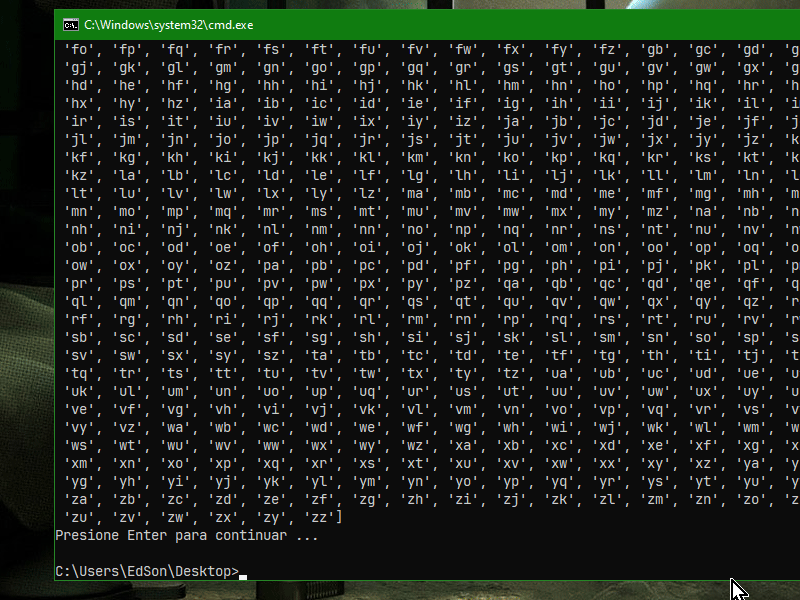 Lo mejor siempre es abrir una línea de comandos y ejecutar el script ahí, en mi caso presiono Shift + Click derecho en un espacio vacío y me aparece en el menú contextual la opción de: Abrir ventana de comandos aquí, luego arrastro el script ahí o tipeo el nombre, al final un Enter para ejecutarlo |
|
|
|
|
En línea
|
|
|
|
|
|
|
EdePC
|
Línea 4, caracter No UTF-8 encontrado. import itertools def cargar_diccionario(ruta): """Carga el diccionario desde un archivo .txt y devuelve un conjunto de palabras en minúsculas.""" with open(ruta, 'r', encoding='utf-8') as archivo: return set(palabra.strip().lower() for palabra in archivo) ...
Lo que te está dando problemas es la palabra min úsculas por la tilde en la u. Y esto ya se explicó en un mensaje anterior donde te pasó lo mismo con la ñ: https://foro.elhacker.net/python/python_falla_en_usar_la_n-t522777.0.htmlLa solución es guardar tu archivo de código python con la codificación UTF-8 o agregar el PEP correcto Guardando con codificación UTF-8 con el bloc de notas de Windows 7 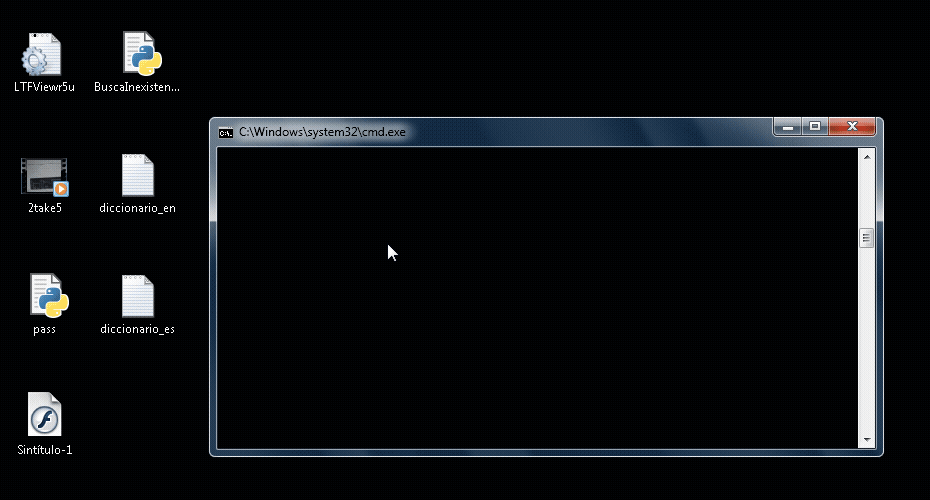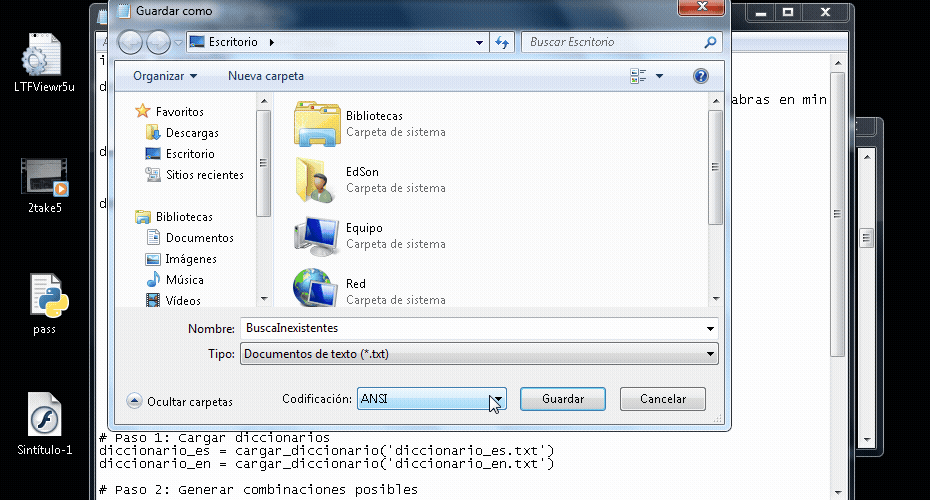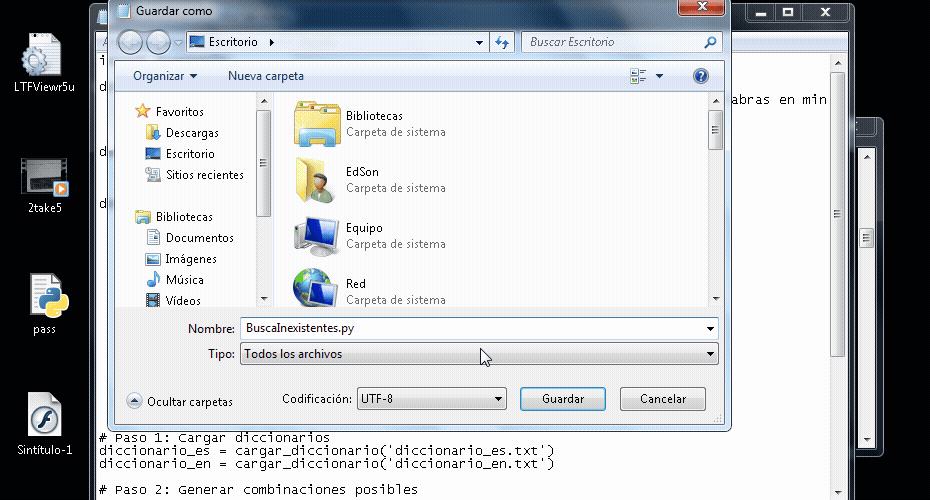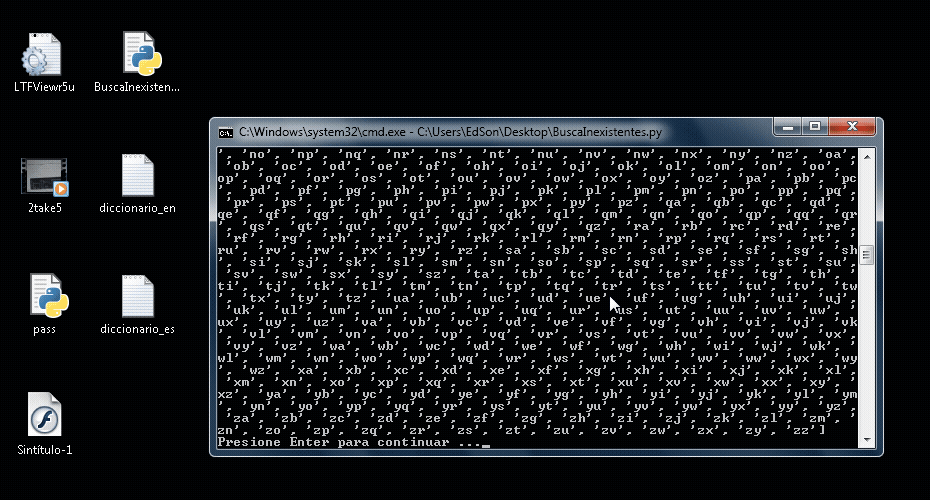 Agregando el PEP correspondiente. El Bloc de notas de Windows 7 por defecto trabaja con ANSI:  Que editor de texto estás usando? usa uno decente como Notepad++ al menos, este ya trabaja en UTF-8 por defecto. Por ejemplo con Notepad++ puedes ver en todo momento bajo que codificación estás trabajando y también te ofrece opciones de conversión de codificaciones comunes 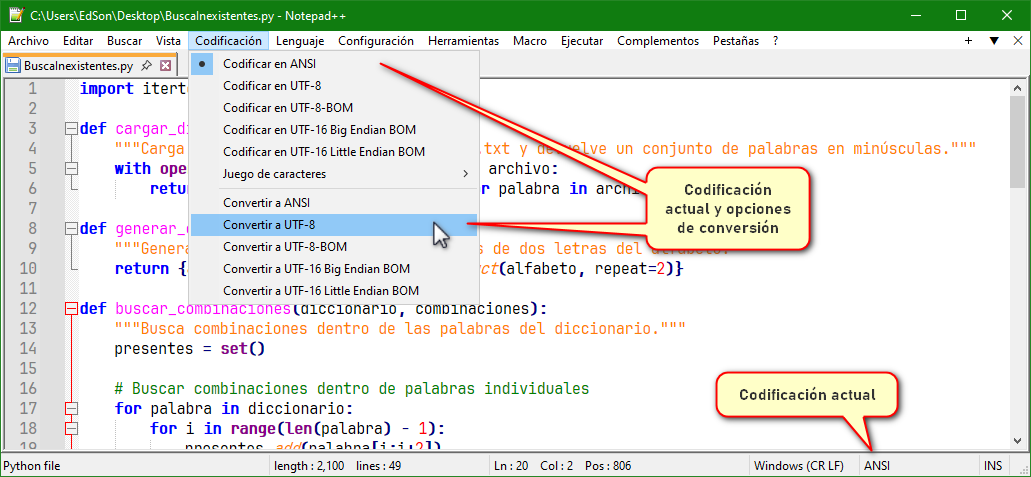 Usa Convertir a UTF-8 para no tener problemas con Python porque Python trabaja por defecto con UTF-8 |
|
|
|
|
En línea
|
|
|
|
Tachikomaia
Desconectado
Mensajes: 1.610
Hackentifiko!
|
Línea 4, caracter No UTF-8 encontrado. import itertools def cargar_diccionario(ruta): """Carga el diccionario desde un archivo .txt y devuelve un conjunto de palabras en minúsculas.""" with open(ruta, 'r', encoding='utf-8') as archivo: return set(palabra.strip().lower() for palabra in archivo) ...
Lo que te está dando problemas es la palabra min úsculas por la tilde en la u. Y esto ya se explicó en un mensaje anterior donde te pasó lo mismo con la ñ: https://foro.elhacker.net/python/python_falla_en_usar_la_n-t522777.0.html Me había olvidado. Pero yo el texto lo veo igual ¿por qué para él es tan diferente? Suena como a que un visor de imágenes no pueda cargar un PNG o algún formato normal, suena limitadito >__< Si el UTF-8 acepta tildes y Python trabaja con UTF-8 ¿por qué si le doy un archivo con un tilde actúa como si le estuviera dando algo que no puede manejar? ¿es que a nivel de lenguaje máquina lo expresa distinto? Que editor de texto estás usando? usa uno decente como Notepad++ al menos, este ya trabaja en UTF-8 por defecto. Uso el Notepad común para muchas cosas por lo liviano que es, Word me pone un cartel de que se está cargando, luego algo de la licencia, los márgenes están mal y la fuente no me gusta, cuando lo uso abro un archivo preesistente que tengo y lo edito, pero en fin, en general me conviene más el Notepad común. Para esto, en cambio, probaré el que dices.
|
|
|
|
|
En línea
|
|
|
|
|
EdePC
|
Word me pone un cartel de que se está cargando, luego algo de la licencia, los márgenes están mal y la fuente no me gusta Obviamente un editor de texto enriquecido como Word no es para editar código, como ya dije usa al menos Notepad++ El Bloc de Notas de Windows 7 utiliza por defecto la codificación ANSI, ya en Windows 10 se usa por defecto UTF-8 Pero yo el texto lo veo igual ¿por qué para él es tan diferente? Suena como a que un visor de imágenes no pueda cargar un PNG o algún formato normal, suena limitadito >__< Tu lo ves normal porque tu editor de texto ha reconocido correctamente la codificación del archivo. Lo mismo debería pasar con los editores de imágenes siempre y cuando detecten bien el formato y soporten ese formado, si por ejemplo hacen la detección por la extensión del archivo pueden tener problemas si el archivo tiene la extensión cambiada, IrfanView hace la detección por su cabecera (primeros bytes del archivo en bruto) así que no le puedes engañar, incluso por defecto ofrece cambiarle la extensión a la correcta y soporta prácticamente todos los formatos de imágenes (si tiene las extensiones instaladas) Si el UTF-8 acepta tildes y Python trabaja con UTF-8 ¿por qué si le doy un archivo con un tilde actúa como si le estuviera dando algo que no puede manejar? ¿es que a nivel de lenguaje máquina lo expresa distinto? Python no se molesta en revisar la codificación del archivo, si no le indicas claramente para él le has pasado uno bajo codificación UTF-8 Y no, no son lo mismo, las codificación más usuales son ANSI y UTF-8, puedes hacer pruebas guardando un archivo de texto con la palabra ñandú que es una palabra clásica para pruebas de codificación, lo guardar bajo esas tres codificación y luego los abres con un editor hexadecimal y verás las diferencias: ANSI Offset(d) 00 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15
00000000 F1 61 6E 64 FA ñandú UTF-8 Offset(h) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
00000000 C3 B1 61 6E 64 C3 BA ñandú ANSI (para lo que puedes ver) utiliza un solo byte para codificar cualquier caracter incluso los caracteres especiales como la ñ y la ú por ejemplo, sin embargo UTF-8 aunque igual utiliza un solo byte para los caracteres comunes (ASCII), ya utiliza dos bytes (o más) para los caracteres especiales, C3 B1 para ñ, y C3 BA para la ú Lo anterior limita a ANSI a poder trabajar con máximo 256 "caracteres" 00 a FF, UTF-8 en cambio puede trabajar con una infinidad de caracteres porque es capaz de codificar caracteres especiales con dos o más bytes. Si por ejemplo eres chino, ruso o japonés y quieres escribir hola en tu código fuente, ANSI no te sirve, debes usar UTF-8, antes tenían que usar imágenes porque UTF-8 no existía o no tan estándar hola en chino bajo UTF-8 ( 你好 => 2 caracteres): Offset(h) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
00000000 E4 BD A0 E5 A5 BD ä½ å¥½ hola en japonés bajo UTF-8 ( こん にち は => 5 caracteres): Offset(h) 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F
00000000 E3 81 93 E3 82 93 E3 81 AB E3 81 A1 E3 81 AF ã.ãã.«ã.¡ã.¯ ---  Ves que te dice error porque ha encontrado el hexadecimal FA (ú) y ese no es un UTF-8
|
|
|
|
|
En línea
|
|
|
|
|
| Mensajes similares |
|
Asunto |
Iniciado por |
Respuestas |
Vistas |
Último mensaje |
|
|

|
buscador en php... q no funciona. AYUDA POR FAVOR
PHP
|
miguelangelss4
|
4
|
3,807
|
 25 Abril 2009, 11:19 am
25 Abril 2009, 11:19 am
por miguelangelss4
|
|
|
|
No funciona mi buscador
GNU/Linux
|
Choclito
|
7
|
5,193
|
25 Diciembre 2010, 08:07 am
por Choclito
|
|
|
|
Buscador de combinaciones numéricas
Dudas Generales
|
hcalderon11
|
0
|
3,770
|
16 Febrero 2012, 21:49 pm
por hcalderon11
|
|
|
|
Google explica a los usuarios cómo funciona el algoritmo de su buscador de....
Noticias
|
wolfbcn
|
0
|
2,605
|
6 Marzo 2013, 22:35 pm
por wolfbcn
|
|
|
|
Un buscador de torrents sin anuncios, enfocado en la privacidad y que funciona
Noticias
|
wolfbcn
|
0
|
1,539
|
20 Enero 2018, 02:14 am
por wolfbcn
|
 |