



 Autor
Autor



La definicion del algoritmo gradient descent, aplicado en backpropagation para entrenar redes neuronales, es la siguiente:
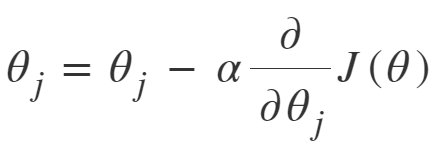
Sin embargo, en el siguiente blog,
https://anderfernandez.com/blog/como-programar-una-red-neuronal-desde-0-en-python/
Se aprecia como se calcula delta de la siguente forma:
Código
La pregunta es:
¿Por que se multiplica delta con W_temp?
¿Cual es el proposito de W_temp en general?
No entiendo en que parte de la definicion original puede caber ese W_temp, o cual es la logica que cumple.
Gracias de antemano y buenas noches.
Ya encontre la respuesta.
Se multiplica por la derivada el error. Esto indica el "factor necesario" para entrenar la red neuronal (es decir, que tan equivocada esta, en terminos de la relacion entre la derivada de la funcion de activacion, es decir, el cambio en la misma, la prediccion).
 En línea
En línea

