| |
 Mostrar Mensajes Mostrar Mensajes
|
|
Páginas: [1] 2 3
|
|
1
|
Programación / Programación C/C++ / Re: Funcion Hash para un diccionario de palabras.
|
en: 14 Mayo 2019, 03:36 am
|
|
Muchas gracias por tu respuesta y tu tiempo, prometo este fin de semana seguir con atención tu respuesta con más calma sin embargo me surge la pregunta de como llegaste a darte cuenta de todos estos aspectos. Durante mi viaje por varias notas y segmentos de libro solo hablan de manera muy superficial sobre como tratar las colisiones y cuales son las caracteristicas de una buena funcion hash sin embargo no he visto una respuestas tan construida como la tuya, supongo que profundizando un poco más sobre los temas de matematicas discretas se podrá fundamentar de mejor manera las conclusiones a las que llegaste pero ¿ Como lograste llegar a ellas ? , no las pongo en duda pero me intriga el saber como fue la construcción de todos estos elementos.
|
|
|
|
|
2
|
Programación / Programación C/C++ / Funcion Hash para un diccionario de palabras.
|
en: 13 Mayo 2019, 04:44 am
|
|
¿Alguien conoce algun algoritmo especifico para generar una función hash eficiente para un diccionario(tabla hash)?
Mi problema plantea el uso de un diccionario que utiliza como generadora del hash una cadena que por el contexto del problema no debería sobresalir de más de 15 caracteres y en promedio tendría un aproximado de 10 caracteres. Hasta ahorita me he empezado a formular una manera de que no existan tantas colisiones en el entero que genera cada string con referencia a que pueden existir string diferentes pero que en si tienen los mismo caracteres, he pensado en varias formas entre las cuales se encuentra por ejemplo multiplicar los valores de cada posion por un valor que no pueda ser generado con la suma de los anteriores es decir:
Cadena "hola"
HASH = 0;
HASH += 'H' ;
HASH += 'O' +167
HASH += 'L' + 334
HASH += 'A' + 501
El factor 167 lo eligo debido a que el último caracter que se usaria en el contexto de mi problema seria las vocales con acento que se encuentran como maximo en el valor 165 del ASCII y de esta manera puedo generar valores distintos para cadenas que contiene los mismo caracteres pero en distintas posiciones
Nota. he considerado hacer este proceso hasta los 6 caracteres como maximo ya que considero que sería muy extraño que dos palabras empiecen con el mismo patron de 6 caracteres y esto solo estaria consumiendo mas tiempo para cadenas un poco mas largas.
Mi duda surge a la hora de adaptar lo que tengo hasta ahorita al arreglo que me va representar el diccionario. Actualmente mi diccionario esta representado por un arreglo de arboles binarios que cuando encuentran colisiones simplemente se añade a una rama del árbol. Mi pregunta es como se hace para ya teniendo un algoritmo generador de hash adaptarlo a la dimension del arreglo que en mi caso es el de tamaño "101". He probado con algoritmos como el anterior y no he conseguido valores de colisiones favorables, he probado con hash algo aleatorios y he conseguido llegar a que la desviacion estandar de las colisiones sea de 2.86 con una media de aproximadamente 8.44 y un total de datos ingresados de 853 pero como menciono no quedo satisfecho debido a que el algoritmo generador de hash no tiene mucho sentido.
ACTUALIZACIÓN. Cuando digo que no se como adaptar lo que llevo hasta ahorita para ingresarlo en arreglo me refiero a que no se como hacer que se distribuya de una manera ligeramente pareja en todas las posiciones , al menos al moment de ahora lo único que hago es relizar un modulo al hash obtenido:
HASH_OBTENIDO % TAMANO_ARREGLO( Es un numero primo)
|
|
|
|
|
3
|
Programación / Bases de Datos / Re: Implementación de una base de datos en un programa local.
|
en: 24 Abril 2019, 17:29 pm
|
|
Planteando que en esta aplicación es de uso personal y no creo que sea necesario más de 1,000 consultas por usuario en una sesión se recomendaría hacer todo directamente a la base de datos? O hacer uso de objetos que me creen un tipo buffet que guarda los datos durante la sesión y los sube finalmente a la base de datos al final de la sesión. Al menos en este programa no sé si llegue a tener alguna ventaja el hacer las consultas directamente a las bases de datos debido a que el programa es local y nunca va tenerte problemas de concurrencia. El gestor que utilizo es MySQL pero más que nada estoy desarrollando el programa con fines de aprendizaje que como algo como formal pero sin embargo me interesa ir pensando en cómo se implementa todo esto de forma correcta
|
|
|
|
|
4
|
Programación / Bases de Datos / Implementación de una base de datos en un programa local.
|
en: 24 Abril 2019, 04:38 am
|
|
Buenas a todos, estoy empezando con bases de datos y he comenzando a crear un sistema pequeño que me permita crear un tipo agenda-directorio por usuarios con su respectivo login etc... Mi planteamiento es primero hacerlo totalmente local, es decir, solo quiero que la cuenta y toda su información sea utilizada dentro de la computadora donde fue creada. Hasta el momento no he visto mucho sobre como se implementan las bases de datos en los programas cotidianos , solo he visto sobre consultas,tablas,etc... Mi principal duda es si en este tipo de programas vale la pena cada vez que agrego/elimino/actualizo un dato de un contacto/cita/etc... ¿ debo hacer la consulta respectiva a la base de datos inmediatamente? o se suele tener un objeto en memoria dinamica que es aquel que se carga al principio del inicio de sesión con una consulta a la bases de datos y que es el que recibe todas las modificaciones para finalmente al final de la sesión o cada cierto periodo tiempo actualiza los datos mediante una consulta a la base de datos. Imagino que si el programa estuviera emergido en un sistema distribuido estaría obligado a manejar mas detalles y todo cambio hacerlo directamente a la base de datos pero en este tipo de programas que suele hacer?. Intuyó que utilizar siempre consultas es un gasto de recursos innecesario pero tal vez no estoy viendo algún detalle importante.
En el caso que por lo general se trabaje con objetos en memoria para los cambios entonces cual seria la mejor forma de por ejemplo verificar que elementos fueron borrados.. yo tendria mi estructura de datos de los datos que tiene el usuario al final de su sesión pero que suele hacer para saber que datos pudieron haber sido eliminado? ,simplemente deberia tener por ejemplo un array que me guarde los id de aquellos elementos que fueron eliminados para al final de la sesión saber que debo eliminarlos?.Supongo que la parte de que se modifico/anadio un nuevo objeto/registro tambien deberia ser analizada con respecto a la esctuctura de datos que tengo verificando al final de la sesión si un dato ya se encuentra en la base de datos.. En dado caso ver si se modifico durante la sesion o en caso de que el elemento no se encuentre en la base de datos hacer un insert
|
|
|
|
|
5
|
Programación / Java / JavaFx transmisiòn de datos entre escenas.
|
en: 21 Abril 2019, 02:52 am
|
Buenas a todos tengo una duda con referencia a como se suelen hacer las interfaces graficas con JavaFx en casos como en el siguiente: Tengo una interfaz gráfica que muestra una parte de información estatica que nunca cambia y tengo una área donde yo eligó una sucursal, esta parte es una tabla(GridPane) que contiene varias botones y que cada botón esta vinculado con una sucursal. Al yo darle clic a cada botón existe una barra lateral que cambia mostrando un listado de todos los articulos disponibles en dicha sucursal. Hasta el momento seria algo así... 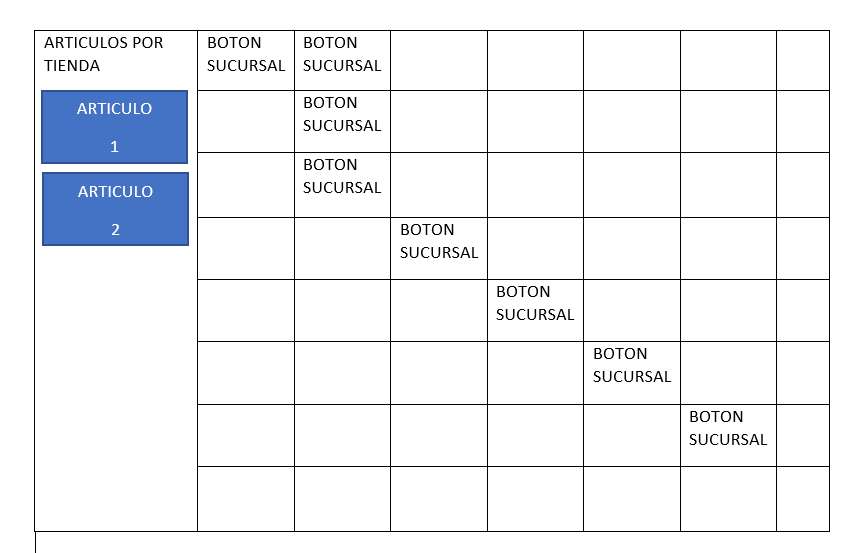 Aún no me pongo a programarlo pero intuyo que el primer acierto que podría hacer es crear una vista-controlador para cada articulo que se muestra en la barra lateral debido a que el numero de articulos que se muestra van a ser variables con respecto al contenido de cada sucursal pero mi pregunta es.. Si yo agregara un botón de eliminar dentro de estos contenedores que representan un articulo como le haría para borrar tanto intermanete el objeto Articulo de mi "Libro articulos"(Se encuentra en el controlador de la escena principal o sea la anterior)como refrescar la vista. Puntualizando mas mi duda... Entendiendo que yo ya hice una clase vista-controlador para representar un articulo entonces esta clase seria una archivo FXML con sus label ,etc,etc.. y un boton que dice "Eliminar" . Lo que se me viene a la mente es que le agregaría en su controlador un atributo de objeto "ARTICULO" que me representaría el objeto que esta mostrando pero como le hago para al detectar el evento clic en el boton "Elimiar" este se regrese a la escena principal, la que contiene objetos como "Libro de Articulos de sucursal tal... " y lo elimine. Se me ocurrio que podria solucionar el problema pasando el objeto "Libro de Articulos de sucursal tal... " a cada Escena que representa un articulo y que dentro de la misma escena se borre el articulo de dicho libro pero necesito regresar otra escena mas para refrescar la eliminacion de forma visual. De una forma mas explicita si yo me encuentro dentro de un botón que esta contenido en una escena como le hago para llegar desde ese boton hacia la escena de su escena y obtener finalmente el controlador de dicha escena que es donde tengo mis objetos como "Libro de Articulos de sucursal tal... " y que es desde donde debo hacer unos cambios cuando se genera un evento en el boton. Seria algo como ..... btnEvento.getScene().getScene().getController();
A este controller le haria cast al controlador que yo habia definido para poder acceder a los atributos que yo lo agregue... Lastima que ya he comprobado que no es tan facil como eso. De antemano gracias por su tiempo.
ACTUALIZACION.Encontre una posible solución dada para el ejemplo planteado. Esto es cuando se carga la escena principal en la ventana. FXMLLoader loader = new FXMLLoader(getClass().getResource("VentanaPrincipal.fxml")); TabPane root = loader.load(); Scene scene = new Scene(root); scene.setUserData(loader); stage.setScene(scene);.......... ........
Cuando se recolecta el controlador de la escena de la escena que en este caso no es mas que escena de la ventana. FXMLLoader loader = (FXMLLoader) btn.getScene().getWindow().getScene().getUserData(); VentanaPrincipalController controller = (VentanaPrincipalController)loader.getController();
Ahora una pregunta un como mas enfocada.. ¿ Generalmente se hace de una manera similar la transferencia de datos en aplicaciones graficas ?, ¿Se le suele dar este uso al metodo setUserData y getUserData ? o ¿Cual es su principal finalidad? |
|
|
|
|
6
|
Programación / Programación C/C++ / Eliminación de nodos en un árbol binario ordenado.
|
en: 5 Abril 2019, 18:52 pm
|
|
Ya he dado con la solución de las operaciones básicas del árbol sin embargo me queda la duda dentro de la operación de eliminación. Durante la operación de eliminación tenemos primeramente dos casos.
1. El nodo ha eliminar es la raíz del árbol.
2. El nodo ha eliminar no es la raíz del árbol.
Independientemente cual sea el caso de los anteriores tenemos las siguientes posibilidades:
1. El nodo ha eliminar no tiene hijos. La eliminación implica simplemente eliminar la referencia de su padre que apuntaba hacia el y liberar memoria.
2. El nodo tiene un único hijo o rama. La eliminación implica que la referencia que tenia el padre hacia el nodo que se va eliminar sea reasignada ahora hacia la rama del nodo que se va eliminar.
3. El nodo tiene las dos ramas. Es aquí donde me surge la duda!!... En mi implementación lo que hice fue buscar el nodo mayor de los menores de las rama que tiene el nodo que se va eliminar, una vez localizado ese era mi candidato que ocuparía el lugar del nodo eliminado por lo tanto para este punto lo que hacia era:
1. Remplazar el nodo a eliminar por aquel nodo que era el mayor de los menores haciendo ajustes como que el padre de este nodo ahora apunte a todo el subárbol que puede que existiría del lado izquierdo del nodo que vamos a usar como remplazo al eliminado.
Hasta este paso creo que estar bien... Mi incógnita queda en que he visto que algunos dan mas seguimiento al caso de que el nodo a eliminar tenga las dos ramas , es decir, primero hacen lo que yo hago... que es buscar la hoja o nodo que es el mayor de los menores del nodo a eliminar,posterior a eso veo que si ese nodo auxiliar o de remplazo tiene su rama izquierda hacen otra comprobación pero ahora por parte del nodo menor de los mayores del nodo a eliminar, es decir, vuelven a hacer lo mismo que yo hice pero ahora con el nodo menor de los mayores. Una vez comprobado esto pueden tener que:
1.El nodo menor de los mayores resulta no tener la rama de la derecha por lo cual es un mejor candidato a ser el remplazo del nodo a eliminar.
2.El nodo menor de los mayores tiene la rama derecha por lo cual hasta este punto tiene el mismo beneficio que el nodo mayor de los menores sin embargo aquí es cuando veo que hacen una segundo cuestionamiento y es ¿ Qué rama tiene menos niveles ?, hacen un conteo de los niveles en caso de que no hayan recorrido antes y finalmente determinan cual es el mejor candidato.
Mi duda es ¿ Realmente vale la pena realizar todo este proceso?, es decir, a mi forma de verlo yo solo modificaría a mi implementación el hecho de que si el candidato del lado izquierdo que es el mayor de los menores del nodo a eliminar tiene alguna rama solo verificaría si el candidato 2 o el candidato menor de los mayores no tiene la rama derecha , en ese caso eligiria el candidato de la derecha( el menor de los mayores ) pero en el caso de que este también tuviera su rama.. directamente pondría a hacer el proceso de poner como remplazo al nodo candidato de la izquierda(mayor de los menores) sin importarme cual es que menor nivel tiene por que yo solo estaría viendo si sus ramas son distintas de null para comprobar si tienen ramas y en caso de que quisiera hacer toda la comparación con los niveles debería recorrer ambas ramas y creo que los beneficios que me podría traer esa segunda verificación podrían ser equivalente a su desventaja.
Me gustaría saber como han hecho las implementaciones en esta parte y si consideran que valga la pena llegar hasta ese detalle de comparar los niveles de las ramas.
|
|
|
|
|
7
|
Programación / Bases de Datos / Algún uso de Statement frente a PreparedStatement
|
en: 31 Marzo 2019, 20:22 pm
|
|
Estoy manejando una base de datos relacional a través de mysql en el lenguaje Java y he notado que el curso que sigo nunca se ha utilizado Statement y en vez de ello siempre usa PreparedStatement para estructurar y ejecutar las consultas. He investigado un poco y he visto que PreparedStatement presenta algunas optimizaciones debido a que 'prepara' la sentencia con anticipación y que ademas de eso evita inyección de SQL si se usan son métodos setString... etc para rellenar los valores de la consulta.
Mi pregunta es ¿ Existe algún uso para Statement ? o siempre va ser mejor optar por PreparedStatement.
|
|
|
|
|
8
|
Programación / Programación C/C++ / Re: Uso de referencias con memoria dinámica [C++]
|
en: 31 Marzo 2019, 05:01 am
|
Creo que no está del todo bien. Pongo acá tu ejemplo añadiendo algunos textos que pueden ayudar: #include <iostream> void anular(int* v, int pos) { std::cout << "la direccion de v es: " << &v << " pero apunta a " << v << " (igual que p)\n"; v[pos] = 0; } int main() { int* p; // sin inicializar. no es NULL // std::cout << p << '\n'; [[error -> no puede accederse a un puntero sin inicializar]] std::cout << "p es una variable que esta en algun lado, su direccion es: " << &p << '\n'; p = nullptr; // se la asigna a p el valor cero (cero de puntero, nullptr no es la macro NULL, es de tipo nullptr_t). std::cout << "p apunta a: " << p << '\n'; p = new int[2]; std::cout << "Ahora p apunta a: " << p << '\n'; std::cout << "pero su direccion sigue siendo: " << &p << '\n'; p[0] = 1; p[1] = 2; anular(p, 1); }
Yo lo diría así: Un puntero es una variable como cualquier otra, en este caso, p es de tipo int*. Como toda variable está en algún lado, se puede tomar su dirección; además se le puede asignar un valor, otra dirección de memoria, aunque esa dirección de memoria que se asigna al puntero puede estar en el free store (memoria libre) o en la pila (stack), a p le da igual. Por ejemplo: int i=5; p = &i; // stack En tu línea 6 tienes declarado el puntero p, pero sin inicializar, no apunta a NULL; probablemente apunte a algo pero no podemos saberlo, intentar acceder a qué apunta un puntero sin inicializar es un error que no debería siquiera compilar. Lo que sí puedes es leer su propia dirección, en dónde está. Entonces, en un puntero tenemos su propia dirección de memoria y la dirección de memoria a la que apunta. Cuando pasas a p como parámetro de anular(), puedes ver que la dirección de v es diferente a la dirección de p, naturalmente, v está en el el stack frame de anular(), pero apunta a la misma dirección que apunta p. Puedes verlo ejecutando mi ejemplo. Si observas los valores reales de las direcciones de memoria a donde apuntan p[0] y p[1] podrás ver que 1) p == &p[0]; 2) &p[1] == &p[0] + sizeof(int*); p y &p[0] podrían llegar a ser de tipos distintos, pero los dos guardan la misma dirección de memoria. Como &p[0] y &p[1] son las direcciones consecutivas en memoria capaces de guardar sendos int(s), deben diferir en sizof(int*), ni más ni menos. ¿ Por qué se dice que la macro NULL no es recomendada en C++ ?, he visto varias fuentes que afirman eso pero no logro entender el por que. Sé que la macro 'NULL' viene desde C y que representa el numero entero 0 y que 'nullptr' fue agregado en C++11 pero ¿ qué problemas puede conllevar el usar la macro 'NULL'. ? |
|
|
|
|
9
|
Programación / Desarrollo Web / Objeto history y sus métodos.
|
en: 28 Marzo 2019, 01:26 am
|
Hola a todos, estoy empezando a curiosear con los métodos del objeto history que forma parte del objeto window dentro del DOM y tenía la curiosidad de en que casos puede ser útil. Creo que entender que el objeto history junto con sus métodos son rutiles cuando se necesitan crear varios estados de una pagina html , es decir, cuando quiero mi pagina de registro cree un estado cada vez que hace focus a una entrada distinta del formulario de esta manera si el usuario da para atrás conseguirá que no se salga de esa pagina html si no que se vaya al estado anterior que simplemente sera la misma pagina pero antes de que hiciera focus a la entrada actual, es un ejemplo poco útil pero ¿ esta bien mi forma de pensarlo ?, a partir de eso he checado un ejemplo como este: Código HTML<!doctype html> <meta name="viewport" content="width=device-width,initial-scale=1"> <link rel="stylesheet" href="style.css"> <div class="box" id="box-1">one </div> <div class="box" id="box-2">two </div> <div class="box" id="box-3">three </div> <div class="box" id="box-4">four </div>
Código JSlet boxes = Array.from(document.getElementsByClassName('box')); function selectBox (id) { boxes.forEach(b => { b.classList.toggle('selected', b.id === id); }); } boxes.forEach(b => { let id = b.id; b.addEventListener('click', e => { history.pushState({id}, `Selected: ${id}`, `./selected=${id}`) selectBox(id); }); }); window.addEventListener('popstate', e => { selectBox(e.state.id); }); history.replaceState({id: null}, 'Default state', './');
Código CSS.boxes { display: flex; } .box { --box-color: black; width: 200px; height: 200px; margin: 20px; box-sizing: border-box; display: block; border-radius: 2px; cursor: pointer; color: white; background-color: var(--box-color); border: 5px solid var(--box-color); font-size: 30px; font-family: sans-serif; font-weight: bold; text-align: center; line-height: 200px; transition: all 0.2s ease-out; } .box:hover { background-color: transparent; color: black; } .box.selected { transform: scale(1.2); } #box-1 { --box-color: red; } #box-2 { --box-color: green; } #box-3 { --box-color: blue; } #box-4 { --box-color: black; }
El programa funciona bien en la navegación del historial hacia adelante y hacia atrás pero mi duda surge conforme a la actualización de la pagina, es decir, cuando yo actualizo la página me sale un error del método get pero desconozco si es posible hacer que esto no suceda y que simplemente se regrese al mismo estado de la página sin que salte ese error. |
|
|
|
|
10
|
Programación / Java / Re: Diferentes formas de manejar eventos en java.
|
en: 25 Marzo 2019, 00:15 am
|
otra es por medio de clases internas anónimas, para no llenar tu clase con implementacion de interfaces
Ejemplo con una expresión lambda, mínimo java 8 debes tener.
button.addActionListener(e -> { });
Ya veo , parece ser una forma muy limpia de hacerlo, aún no he tocado el tema de las expresiones lambda pero veo que es muy similar a la forma en que se hace esta tarea en javascript. |
|
|
|
|
|
| |
|
