| |
 Mostrar Temas Mostrar Temas
|
|
Páginas: [1] 2
|
|
1
|
Seguridad Informática / Nivel Web / Fingerprinting with local HTML files
|
en: 23 Septiembre 2014, 14:24 pm
|
[list=1] Inicio
La Idea
Inconvenientes
Pruebas
[list=2] Firefox
IExplorer
Chrome
Safari[/list]
Más ideas
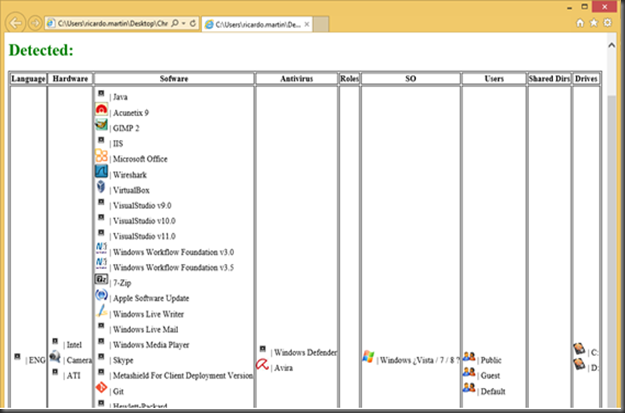
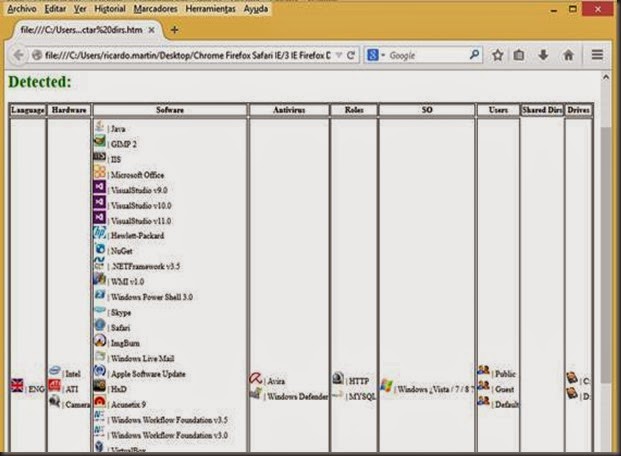
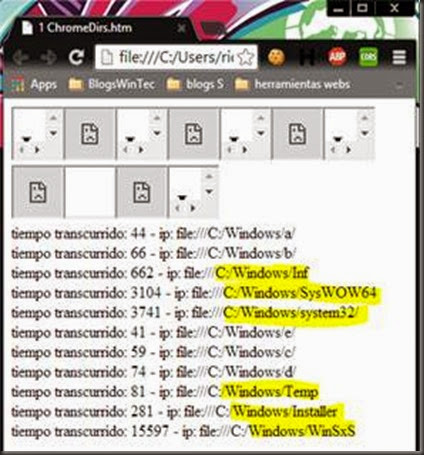
Planteamiento del ataque[/list] InicioEl tema del siguiente articulo como bien dice el titulo se trata de la recopilación de información del sistema mediante un fichero HTML que se encuentre almacenado en local. Esta técnica que hago pública pretende ser una alternativa a la recopilación de información de un sistema mediante un tipo de fichero no comúnmente utilizado para este fin, que va a resultar menos sospechoso que un binario, evidentemente esta técnica no se puede comparar con la cantidad de información que puede recabar otras herramientas spyware pero como bien digo es una alternativa. La ideaLa idea básicamente es utilizar el esquema URI file:// para apuntar mediante una etiqueta HTML a un recurso de la maquina en la que se abre el fichero HTML y apoyándose en javascript, más concretamente en los eventos o en el tiempo de retardo de los mismo o en la ausencia de estos, poder identificar si ese recurso existe o no, más delante se detallará más este concepto. Inconvenientes javascript: Puede ser que se esté bloqueando la ejecución de javascript en la página web que recoge la información del sistema. Esquema URI file://: El inconveniente de este esquema URI es que no puede ser utilizado si la aplicación web que lo utiliza para hacer referencia a un fichero la brinda un servidor web, o lo que es lo mismo, solo se puede utilizar si la aplicación web que utiliza este esquema URI se abre desde la máquina de la víctima. PruebasCon IExplorer es posible detectar los recursos internos de un sistema en el ejemplo siguiente, detectar los directorios de aplicaciones cuando el evento javascript onLoad no es llamado, es decir que cuando un recurso no existe el evento onLoad es llamado y por el contrario cuando existe no lo es. En la imagen que se muestra a continuación se puede ver una lista que se determinar cómo se ha explicado antes, dependiendo de si el navegador no llama al evento onLoad cuando se haga referencia a un directorio existente mediante un iframe. <iframe src=file://C:/ onLoad=alert(NO EXISTE)>Con Firefox al contrario que con IExplorer es posible determinar de si el directorio al que se apunta existe SI el evento onLoad es llamado. <iframe src=file://C:/ onLoad=alert(EXISTE)>Como conclusión para IExplorer y Firefox se puede decir según las imágenes que es posible determinar: el lenguaje del sistema, el hardware en base al software instalado, software instalado, antivirus, sistema operativo, por fuerza bruta usuarios en el sistema, directorios compartidos, unidades de disco, etc. Para Chrome no es tan fácil ya que no se puede en base a eventos determinar nada ya que los eventos son llamados existan o no los directorio utilizando iframe, sin embargo si se puede determinar los directorios con grandes cantidades de ficheros y subdirectorios en base al tiempo de retraso en el renderizado de los mismos. En el siguiente ejemplo se apunta a cinco directorios que no existen y a seis que si, como se puede apreciar los que si existen y que además tienen gran cantidad de elementos tardan mucho más en llamar al evento onLoad que va a servir para calcular el tiempo entre la creación del iframe y el final de la cargar del recurso. Por ultimo hablar sobre el tratamiento de Safari que cuando la etiqueta apunta a un directorio desde un iframe, el funcionamiento de este se traducía en lanzar un explorador de Windows apuntando al directorio que se había establecido en el atributo src del iframe, entonces dejando de lado la posibilidad de detectar los directorios de forma discreta lo que quedaba era realizar un ataque que se basa en añadir una cantidad ingente de iframe apuntando a directorios existentes del sistema por ejemplo a la unidad C: con ello se consigue que el escritorio de la víctima se vea inundado de ventanas del explorador de Windows. Más ideasEstos problemas de eventos, ausencias de ellos o retraso en los mismos, o como sucede con Safari que abre un explorador de Windows, no suceden cuando se apunta a imágenes u otro tipo de ficheros según el tipo de etiqueta utilizada. <img src="file://C:/test.pngs" onload="alert('existe')">
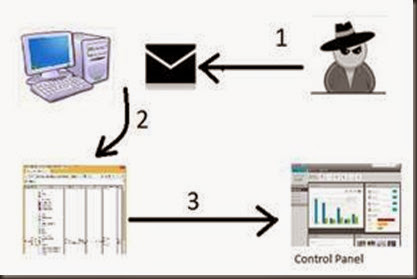
<img src="file://C:/no-existe.pngs" onload="alert('existe')">Funcional en Chrome, IExplorer, Safari, Firefox. De esta forma se podría realizar un script que además de apuntar a directorios apuntase a imágenes, css, js etc para obtener más información del sistema. Planteamiento del ataqueY para acabar el articulo exponer un simple escenario de ataque donde intervienen un atacante(1) que envía un correo donde adjunta un fichero HTML(2) que va a recabar información del sistema de la víctima y este enviara a un panel de control(3) toda esa información donde a posterior visualizara el atacante. Fuente: http://code-disaster.blogspot.com.es |
|
|
|
|
2
|
Seguridad Informática / Nivel Web / Tip para inyecciones en Mongo DB
|
en: 17 Septiembre 2014, 08:34 am
|
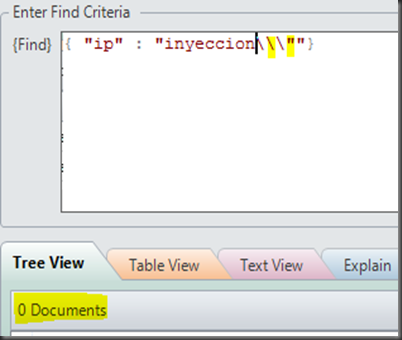
En auditorías donde nos encontramos ante bases de datos NOSQL como puede ser Mongo DB uno de los problemas con los que nos solemos encontrar al igual que con bases de datos SQL es el filtrado de los parámetros enviados, este filtrado con la idea de combatir inyecciones se suele centrar en el remplazo o escapado de caracteres como las comillas simples o las dobles y las backslash, pero como veremos en este artículo a veces cuando nos encontramos ante ciertas situaciones es posible sin necesidad de escapar los caracteres entre los que se encuentra enjaulado el parámetro existe posibilidad de obtener todos los resultados de una colección. En el ejemplo siguiente, si se estuviesen filtrando caracteres como las comillas simples o las dobles y las backslash no podríamos inyectar otra instrucción
{ "ip" : " Parámetro_enviado_por_GET "}Sin embargo si nos encontrásemos con un escenario como el siguiente que aun no siendo tan común es posible, no sería necesario escapar los caracteres anteriormente mencionados para poder armar una buena en la auditoría por ejemplo listando todos los resultados de la colección. { "ip" : { $regex: ' Parámetro_enviado_por_GET ', $options: 'i' }}Y es que como veremos a continuación, basta con añadir dos caracteres que raramente son tenidos en cuenta a la hora de filtrar los datos de entrada a la aplicación Así de sencillo dos puntos o cualquier otro carácter y un asterisco y como se aprecia nos devuelven todos los resultados de la colección, en este caso 50, así que ya sabéis chavales añadid un caracter cualquiera y un asterisco a vuestros diccionarios de inyecciones que os pueden dar una grata sorpresa en vuestras auditorías, a mí me la dio, ya que me devolvieron todos los usuarios y sus datos de la colección ordenaditos en una tabla, que más se puede pedir. Fuente: http://code-disaster.blogspot.com.es/ |
|
|
|
|
3
|
Seguridad Informática / Nivel Web / DS_Store Analyzer Online
|
en: 4 Septiembre 2014, 09:10 am
|
Bueno para los que no lo sepan los ficheros DS_Store son originales de los sistemas Mac OS que están ocultos, y se encarga el propio Finder de crearlos con información del tipo de vista, iconos, columnas, etc, aparece la configuración de la personalización del directorio donde se ha creado, además de los nombres de los ficheros y directorios que cuelgan de él y por este detalle desde el punto de vista de la seguridad existe una fuga de información, ya que los usuarios incautos al mover directorios en un Mac OS a su servidor web accesible por cualquiera revela ficheros y directorios que tal vez no podrían listarse de otra forma. Hace algún tiempo hice una tool en Java y en C# para obtener nombres de ficheros y directorios ocultos en los ficheros .DS_Store, ya por fin traigo una aplicación online para analizar estos ficheros que encuentro en mis auditorías. Lo cierto es que hacía tiempo que andaba con la idea de hacerla online pero por una cosa u otra además por lo cansado que termino cuando llego del curro pues la he ido dejando aparcada, al final aprovechando mis vacas en Fuerteventura me he puesto y la he terminado.  Imagen1: DS_Store Analyzer Online La característica más interesante a remarcar de la aplicación, es la cantidad de patrones de búsqueda utilizados para encontrar los nombres de los ficheros y directorios en el archivo DS_Store. Patrones de búsqueda: Ilo, icg, lg1, moD, ph1, lsv, vSr. Más adelante mi intención es tener la opción de devolver los resultados en XML o JSON. Y sin más les dejo el enlace http://disaster-lab.itsm3.com/ds_store.phpFuente: http://code-disaster.blogspot.com.es/ |
|
|
|
|
4
|
Seguridad Informática / Nivel Web / XSS con Double URL Encode
|
en: 27 Junio 2014, 14:16 pm
|
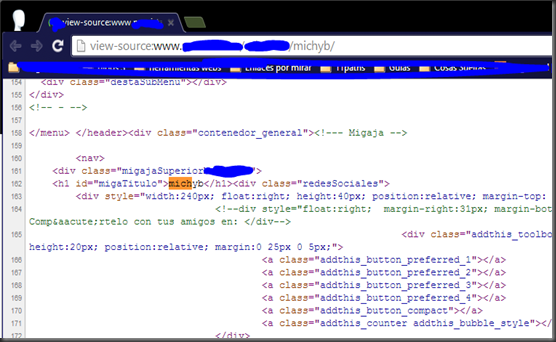
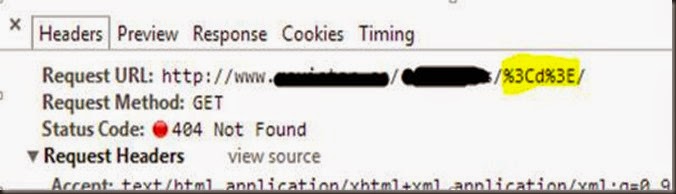
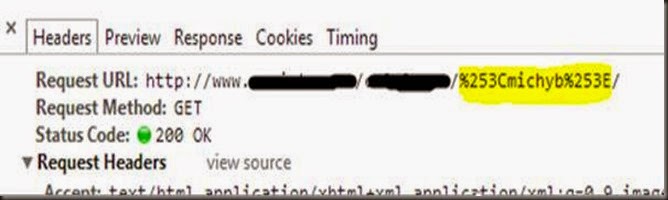
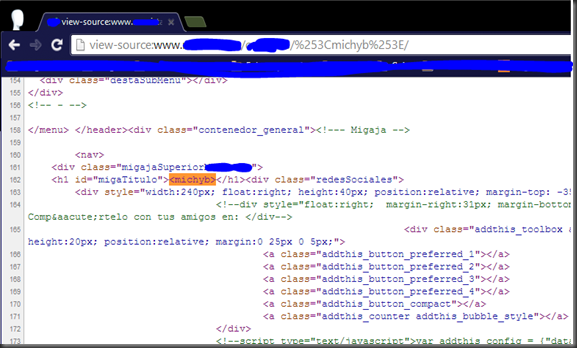
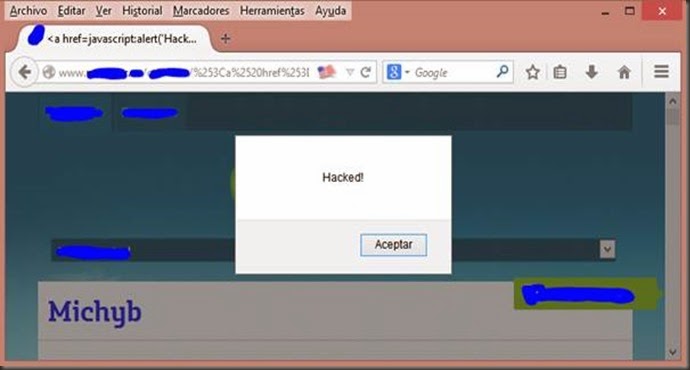
Después de tanto tiempo sin postear nada, traigo un XSS de esos que tan pocos se encuentran y que merecen de una entrada en el blog, ando liado y es cierto que no posteo hace mucho, igual voy encontrándome con casos extraños en el curro y los voy guardando para cuando tenga tiempo darle salida, como lo estoy haciendo hoy con este como poco raro XSS. Bueno, deciros que esta inyección se encuentra en un path ya sabéis mod_rewrite, como ya he venido haciendo otras veces por confidencialidad el enlace es cambiado completamente tanto el dominio, como el resto, que luego deis con él dorkeando jeje. http://www.xxxxxx.com/imagenes/michyb/Como se puede ver la cadena michyb aparece en el HTML devuelto, en la etiqueta TITLE, en la etiqueta META dentro del atributo CONTENT y dentro de un DIV, pero el problema con el que me veo no se soluciona escapando de un atributo de una etiqueta si no como aparece en el título de la entrada se trata de hacerle un double url encode para poder explotar una inyección XSS. Para ello nos vamos a centrar en la etiqueta DIV y vamos a ver cómo reacciona la web ante estos caracteres <d>. Al inyectar <d> nos da un error 404 Not Found esto tiene pinta de tener implementado algún WAF. Después de esta prueba realice dos pruebas más para ir averiguando de qué se trataba. www.xxxxx.com/imagenes/michyb>/www.xxxxx.com/imagenes/<michyb/ En los dos casos, el primero para conocer si se trataba del carácter > y el segundo para el <, en las dos pruebas me devolvía un 200 como Status Code, con lo cual no se trataba de alguno de estos caracteres por separado, así que me decidí por probar un double url encode. 1 encode: %3Cmichyb%3E 2 encode: %253Cmichyb%253E Con double url encode la inyección en la URL quedaría así y como se ve en la respuesta nos devuelve un 200 en el Status Code http://www.xxxxx.com/imagenes/%253Cmichyb%253E/Y Bingo!! Como se ve en el HTML devuelto de la respuesta se encuentra la cadena <michyb> y con ello logramos saltarnos el WAF e incluir etiquetas de cualquier tipo. Así que lo último que queda es probar el mítico alert que de veracidad de la explotación, para ello tuve que tener en cuenta que cualquier inyección no era válida ya que es una inyección en el path y no puede llevar ningún slash ya que lo trataría como otro directorio. Así pues me decidí por un <a href=javascript:alert('Hacked!') >Michyb y el resultado fue. Saludos y hasta la próxima. Fuente: http://code-disaster.blogspot.com.es/2014/06/xss-con-double-url-encode.html |
|
|
|
|
5
|
Seguridad Informática / Nivel Web / Facilitando las auditorias con Google Hacking + AAD
|
en: 19 Diciembre 2013, 10:43 am
|
Cuando necesitamos auditar una web y queremos tirar de los resultados de google hacking uno de los trucos que suelo tener en cuenta es tirar del operador -inurl: para descartar aplicaciones, variables de aplicaciones incluso dominios que ya he comprobado. Un ejemplo sería el siguiente. http://www.tussam.es identifico la tecnología que voy a auditar en este caso php. 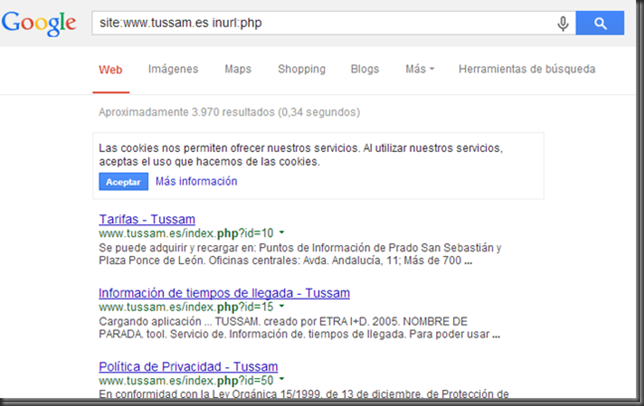 Imagen 1: Búsqueda con Dork sin exclusión Entro en el primer resultado compruebo que no haya nada interesante y vuelvo a realizar la búsqueda descartando la variable id ya que he comprobado que no es vulnerable 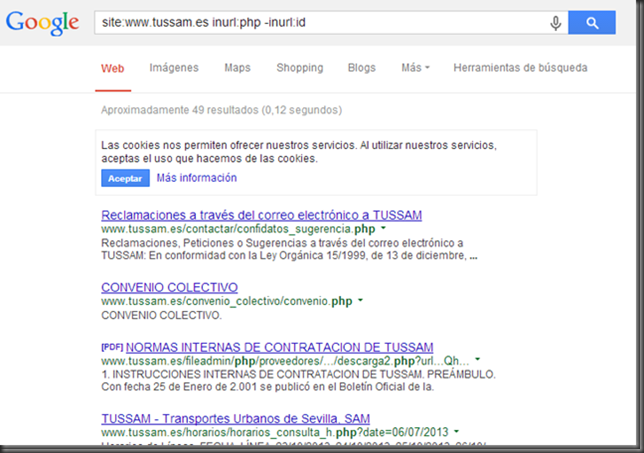 Imagen 2: Búsqueda con Dork con exclusión El problema de esta consulta es que pueden existir otras aplicaciones o directorios en la web que no contengan precisamente en la variable la cadena id, con lo cual estaríamos descartándola, pero sin embargo seriamos capaces de añadir más cantidad de operadores excluyentes si solo nos fijamos en las variables Fijémonos entre la cantidad de exclusiones sin pasarnos del límite de palabras en la consulta, entre dominio+aplicación+variable (Primeros 2 bloques) y solo variable (último bloque). Google8 operadores sobrepasa el límite site: www.tussam.es inurl:php -inurl: www.tussam.es/index.php?id= -inurl: www.tussam.es/index.php?id= -inurl: www.tussam.es/index.php?id= -inurl: www.tussam.es/index.php?id= -inurl: www.tussam.es/index.php?id= -inurl: www.tussam.es/index.php?id="www" (y las palabras que le siguen) se ignoró porque limitamos las consultas a 32 palabras. GoogleBúsqueda Exacta (la ideal) Sin pasarme del límite 7 operadores site: www.tussam.es inurl:php -inurl: www.tussam.es/index.php?id= -inurl: www.tussam.es/index.php?id= -inurl: www.tussam.es/index.php?id= -inurl: www.tussam.es/index.php?id= -inurl: www.tussam.es/index.php?id=BingBúsqueda Exacta (la ideal) 13 operadores sin pasarme del limite site: www.tussam.es -instreamset:(url):php -instreamset:(url): www.tussam.es/index.php?id= -instreamset:(url): www.tussam.es/index.php?id= -instreamset:(url): www.tussam.es/index.php?id= -instreamset:(url): www.tussam.es/index.php?id= -instreamset:(url): www.tussam.es/index.php?id= -instreamset:(url): www.tussam.es/index.php?id= -instreamset:(url): www.tussam.es/index.php?id= -instreamset:(url): www.tussam.es/index.php?id= -instreamset:(url): www.tussam.es/index.php?id= -instreamset:(url): www.tussam.es/index.php?id= -instreamset:(url): www.tussam.es/index.php?id=GoogleBúsqueda en base a las variables GET Sin pasarme del límite. 30 operadores con variables 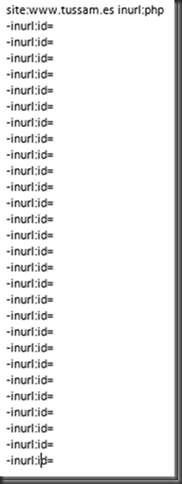 Bing BingSin pasarme del límite. 20 operadores con variables 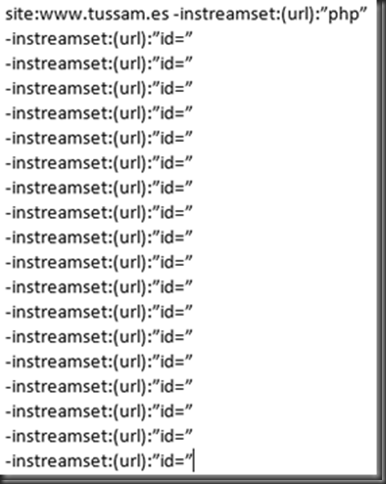 ¿Vale la pena correr el riesgo basándonos solo en las variables? por supuesto que sí, tenemos más cantidad de exclusiones. Filtrando correctamente con Google el límite ronda los 7 operadores mientras con Bing llegamos a 13 operadores sin pasarnos. En cambio filtrando en base a las variables, Google con 30 frente a los 20 permitidos por Bing, queda claro con cual nos quedaríamos por ello hay que decir que Google la tiene más larga con 30 contra 20 de Bing y es que aquí el tamaño sí importa jeje. Bueno pues hice una herramienta para automatizar este proceso, que trabaja con google y con su querido captcha problema que no tenemos con Bing La herramienta tiene el siguiente aspecto. 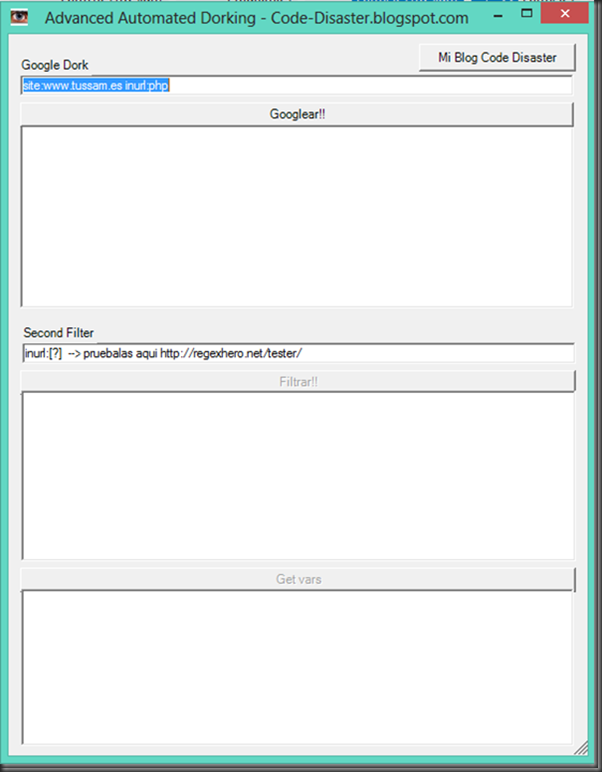 Imagen 3: AAD Interfaz Simplemente es necesario que en la primera entrada de datos se le envié el dork intentando filtrar lo más posible los resultados, por ello que filtro también por la tecnología para evitar html, jpg, png, etc, de este modo acortar los resultados. En el segundo filtro se puede especificar con una expresión regular por ejemplo [?] de este modo aparecerían todas las urls parametrizadas, y es que a quien no le gustaría que a google se le pudiesen pasar expresiones regulares eh? El que no le guste que tire la primera piedra
¬¬ vale sigamos. Y la última opción que sirva para ver los operadores de exclusión con las variables GET encontradas en la web. 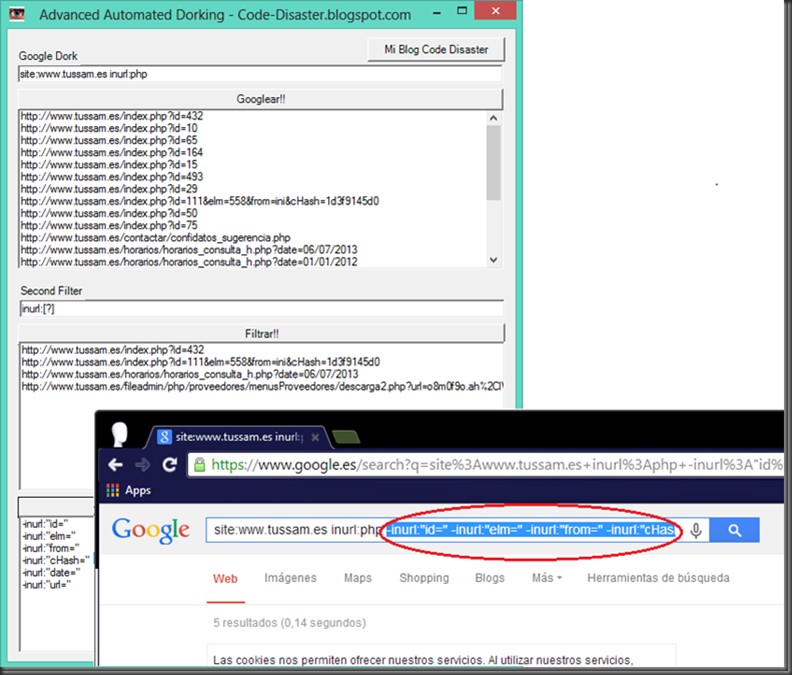 Imagen 4: ADD en acción y abajo misma ultima búsqueda de ADD pero en el buscador Y hasta aquí este post espero que os haya gustado y es que últimamente no posteo tan seguido por que ando liado con la FaasT y cuando llego a la casa estoy sExo polvo :p. Salu2!; Se puede descargar de aqui: https://sourceforge.net/projects/aadgoogle/Fuente: http://code-disaster.blogspot.com |
|
|
|
|
6
|
Seguridad Informática / Nivel Web / Cómo aprovechar el autofill de Chrome para obtener información sensible
|
en: 15 Octubre 2013, 19:59 pm
|
A finales de 2010, Google introdujo en Chrome autofill, una característica cómoda, pero que puede suponer un problema de seguridad para sus usuarios. Incluso después de que otros navegadores sufrieran problemas de seguridad relacionados con esta funcionalidad, y que la funcionalidad en sí haya sido cuestionada, sigue siendo posible robar la información almacenada del usuario que rellena un formulario sin que lo perciba. En general, almacenar datos sensibles en el navegador no suele resultar una buena idea. Justo antes de que Chrome implementara el "Autofill", en verano de 2010, se descubrió cómo sacar todos los datos almacenados en Safari con fuerza bruta en javascript. El usuario rellenaba un campo pero el navegador se encargaba de rescatar todos los demás almacenados, probando todas las letras y dejando que el navegador hiciera el resto. La vulnerabilidad fue parcheada poco después. No hace tanto, en agosto de 2013, se criticó desde muchos frentes lo sencillo que era recuperar contraseñas almacenadas en Chrome, que podían observar en texto plano. Con un sencillo método se puede conseguir que el usuario que escribe en un formulario, entregue esos datos a un tercero sin que sea consciente de ello. ¿Cómo funciona?Autofill de Chrome permite almacenar la dirección postal (dividida en otros datos como nombre, apellidos, teléfono, código postal...) y la tarjeta de crédito (dividida en titular, número y fecha de caducidad). Los datos (excepto la tarjeta de crédito) se pueden sincronizar con la cuenta de Google. El menú de configuración y cómo acceder a él, se observa en la siguiente secuencia de imágenes.  Imagen 1: Configuración del autofilling. 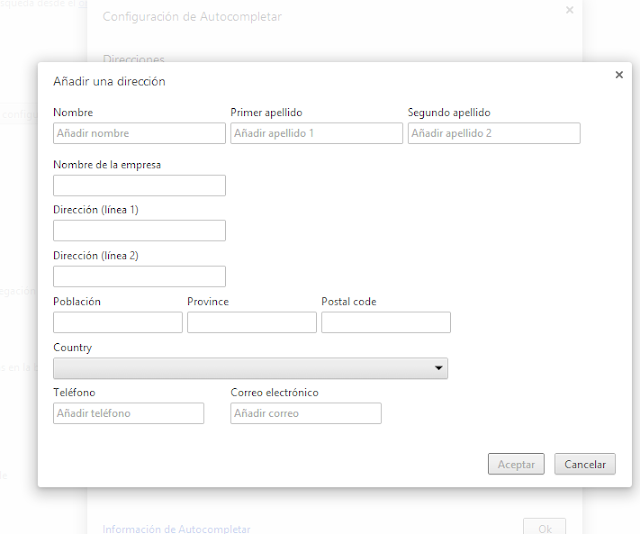 Imagen 2: Configuración del autofilling (Direcciones). 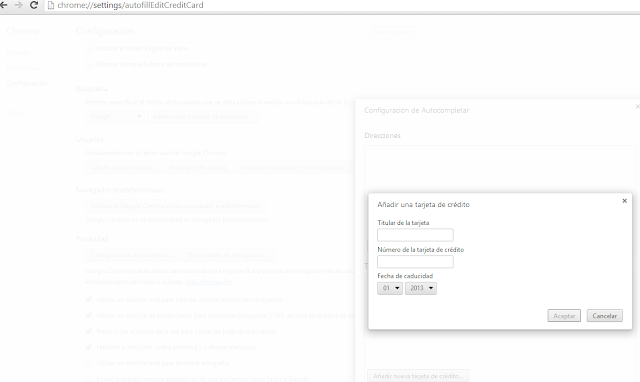 Imagen 3: Configuración del autofilling (Tarjetas de crédito) Diferentes pantallas de configuración de "autofill" en Chrome Para que un formulario aproveche el autofill, los inputs deben ser debidamente identificados para que Chrome sepa qué valores corresponden. 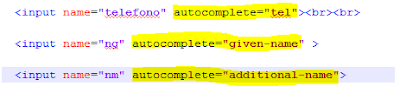 Imagen 4: Atributos para el autofilling Dispone de cierta heurística para intentar que casen los campos. Por ejemplo sabe que autocomplete="mail" debe ir autocompletado con el mismo contenido que cuando lleva de valor autocomplete="Work email". El "ataque"Un atacante puede aprovechar esta característica del navegador para obtener información privada como puede ser los datos del domicilio o datos de la tarjeta bancaria. Planteamos un escenario en el que la víctima visite una página web por https especialmente modificada, introduzca los datos y el atacante se ayude del autofill que ofrece el navegador para obtener datos sensibles almacenados. Todo esto a pesar de las pequeñas trabas que introduce Chrome en su código para evitarlo. Por ejemplo, como precaución, Chrome solo proporciona la tarjeta de crédito a páginas bajo https. Esto no es ningún problema para un atacante, pues es solo tiene que operar a través de una conexión SSL. Existen páginas fraudulentas que funcionan con certificados gratuitos. El segundo paso es preparar el formulario y ocultar a los ojos de la víctima, los inputs que interesan al atacante. La primera aproximación pensaría en utilizar la etiqueta "hidden". Pero en el input el atributo type no puede llevar ese valor. Una segunda aproximación podría ser introducir el formulario dentro de un div con la propiedad visibility en "hidden"... pero Chrome evita que los inputs sean auto-rellenados cuando se cumplen estas condiciones. ¿Cómo conseguirlo entonces? Una fórmula puede ser aprovechar la propiedad de scroll, subiendo la capa algunos píxeles para que no se observen el resto de inputs en los que se pretende recopilar la información. En este caso, el formulario "gancho" se vería:  Imagen 5: PoC Autofilling Pero, usando este "div", conseguimos que en su interior se oculten todos estos inputs y no se visualicen en el navegador: div style ="overflow:hidden;height:25px;"  Imagen 6: Campos ocultos en el formulario. Chrome rellenará toda la información adicional sin que la vea el usuario. El atacante, recopilará la información y podrá disponer de muchos más datos de los que cree haber rellenado el usuario. 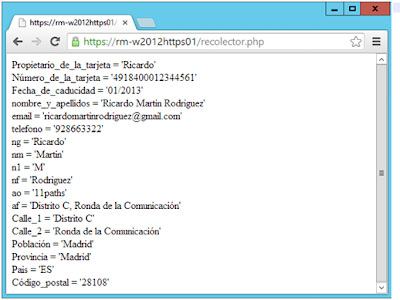 Imagen 7: Recolección de los datos robados. En resumen, aunque resulte cómodo (para sistemas usados por una misma persona solamente), debe evitarse el uso de la funcionalidad autofill, puesto que se ha demostrado que es posible ofrecer a cualquier página bajo https datos tan sensibles como el número de la tarjeta de crédito y su fecha de caducidad, sin que la víctima sea consciente. Para evitar este problema (o potenciales en el futuro), por ahora el mejor remedio es simplemente no utilizar esta funcionalidad. Fuente: http://code-disaster.blogspot.com/ |
|
|
|
|
7
|
Seguridad Informática / Nivel Web / Inyecciones en inyecciones SQL
|
en: 2 Octubre 2013, 20:54 pm
|
La entrada que traigo hoy, trata de como llevar un paso más haya las Union Based SQL Injection, por ejemplo si en algún caso nos vemos frente a una inyección SQL de este tipo, que no contiene datos aprovechables, como pueden ser subir una webshell u obtener las credenciales para acceder al login del gestor de la web que se esté auditando, etc. Se ha de tener en cuenta que un ataque como el Union Based SQL Injection se puede aprovechar de otras formas, y una de estas formas es la que hoy expondré. Se trata ni más ni menos que aprovechar los campos imprimibles de la consulta SQL que por debajo está realizando la página web al cambiar los parámetros que se envían por la url. Aprovechándonos de dicha forma lograr inyectar además de la inyección SQL, código javascript, HTML o por qué no realizar un SSI, de este modo podríamos desde ejecutar comandos en una Shell devuelta por el sistema que se muestra en la página (SSI), incluir un iframe para cargar un exploit (HTMLi), leer las cookies, suplantar un formulario como vimos en uno de los anteriores post de este blog http://code-disaster.blogspot.com.es/2013/08/ataques-xss-avanzados-aplicaciones-webs.html; o cualquier otro que se nos ocurra, y es que de esta forma se lograría explotar otro tipo ataque que tal vez por estar bien protegida la web no se podría dar y con ello otra forma de ownear la web. A continuación se puede ver un ejemplo de una inyección XSS sobre una inyección SQL ya que no se logró explotar de otra forma un XSS en lo demás de la web, siendo irrelevantes los datos obtenidos en la base de datos. 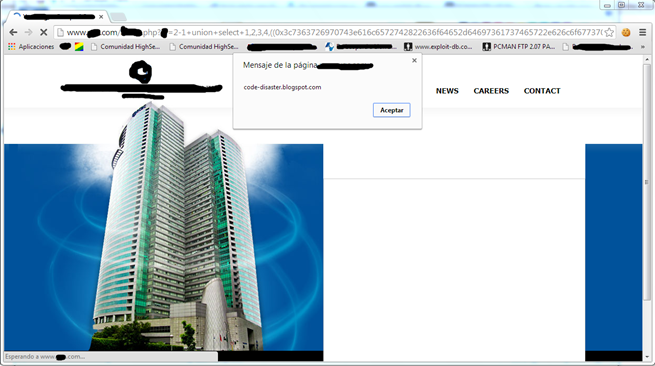 Imagen 1: XSS con SQLi en Google Chrome. Imagen 1: XSS con SQLi en Google Chrome.Otro punto a favor de realizar una inyección XSS de esta manera, es que se consigue Bypassear tanto los filtros Anti-XSS de navegadores como Google Chrome (Versión 29.0.1547.76 m) como los de IExplorer (10.0.9200.16660). 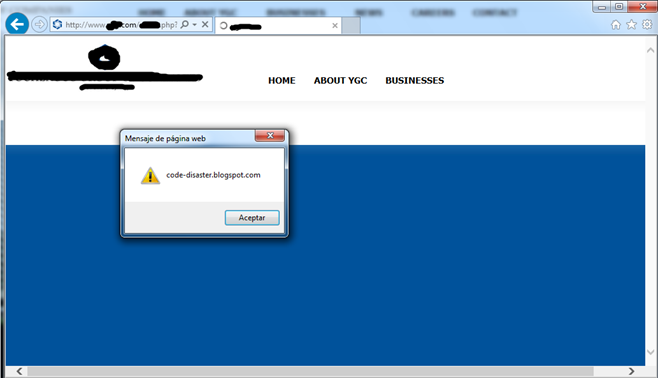 Imagen 2: XSS con SQLi en IExplorer. Imagen 2: XSS con SQLi en IExplorer.Para realizar este ataque se debe primero preparar la inyección SQL de modo que quede así. http://www.localhost.com/test.php?Op=2-1+union+select+1,2,3,4,5,6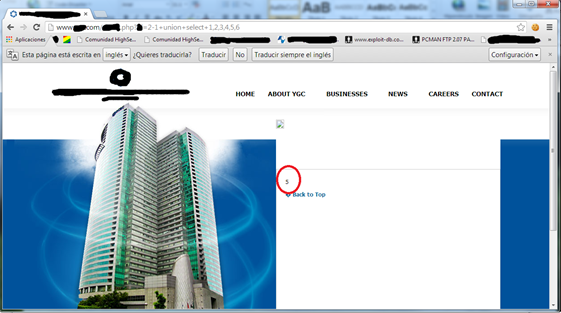 Imagen 3: Búsqueda del campo imprimible. Imagen 3: Búsqueda del campo imprimible.Como se puede apreciar el campo imprimible es el que cae en el 5, entonces será cuestión de sustituirlo en este caso por la inyección XSS cifrada en Hexadecimal con cualquier conversor de Ascii a Hex. Ascii: <script>alert("code-disaster.blogspot.com")</script> Hex: 3c7363726970743e616c6572742822636f64652d64697361737465722e626c6f6773706f742e636f6d22293c2f7363726970743e y por ultimo concatenar a la inyección SQL junto con dos paréntesis de apertura al principio, más 0x (que sirve para identificar el cifrado en el gestor de base de datos y que luego va a servir para devolverla impresa en la web en texto plano), más la cadena en Hex y dos cierre de paréntesis al final. ((0x3c7363726970743e616c6572742822636f64652d64697361737465722e626c6f6773706f742e636f6d22293c2f7363726970743e ))Quedando así. http://www.local.com/test.php?Op=2-1+union+select+1,2,3,4,((0x3c7363726970743e616c6572742822636f64652d64697361737465722e626c6f6773706f742e636f6d22293c2f7363726970743e)),6Fuente: http://code-disaster.blogspot.com/ |
|
|
|
|
8
|
Seguridad Informática / Nivel Web / Acceso a la cuenta de usuario directamente a través de url sin previo login
|
en: 11 Septiembre 2013, 19:26 pm
|
Esta es una práctica que al parecer se está utilizando cada vez más, ya son varias webs que me encuentro con esta forma de acceder a la cuenta de un usuario sin previa autenticación y que encima no caducan las urls pasado cierto tiempo. A continuación voy a explicar algunas de las ventajas para un atacante e inconvenientes para los desarrolladores en cuanto al uso de este método. RefererEl Referer sería un vector para obtener estas jugosas urls algo simple de lo que se podría sacar el acceso a la cuenta de la víctima es como si en el Referer se transmitiera las credenciales. Un ejemplo sería realizando una aplicación que recoja los Referer y pidiendo a la víctima que acceda a la web donde se encuentra esta aplicación donde se obtendrán estas urls que transmiten el key para entrar como usuario logead. Ficheros del historial de los navegadoresOtro causa de por qué no utilizar este método y otro truco de como robar estas urls como todas las otras por las que el usuario navega es el fichero donde se guarda el historial de navegación por ejemplo en Google Chrome con Windows 8 se haya en un fichero que se encuentra en C:\Users\RootedLab\AppData\Local\Google\Chrome\User Data\Default\History Index 2013-09 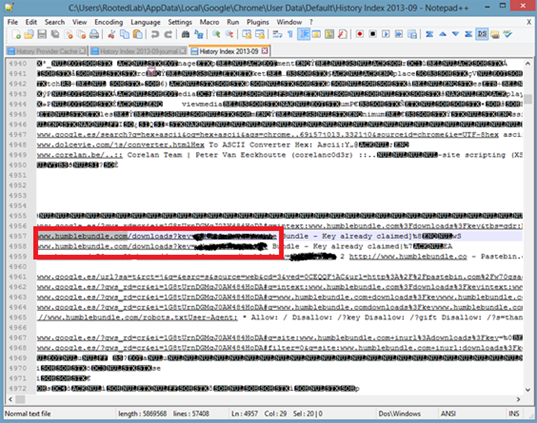 Imagen 1: Historial de Chrome Un ejemplo es el caso de www.humblebundle.com se dieron cuenta un poco tarde sin poder evitar la indexación de sus urls ya que como se puede ver en la segunda imagen se encuentra configurado el robots.txt para deshabilitar que se indexe estas urls pero como se ve en la primera imagen se dieron cuenta algo tarde ya que hay indexadas bastantes de ellas con acceso a la cuenta aunque ya reclamadas, por ello esta sería otra truco a tener en cuenta 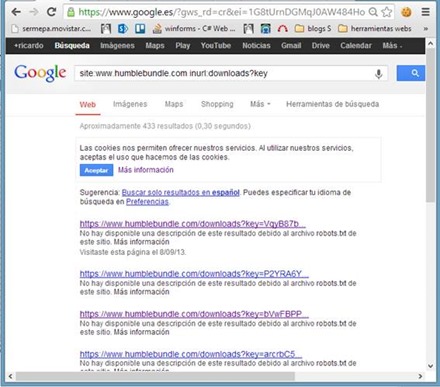 Imagen 2: Urls de acceso indexadas 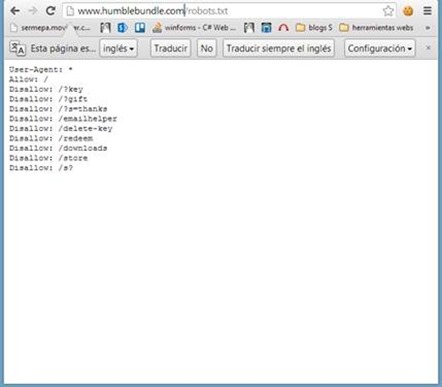 Imagen 3: Robots.txt Casos de webs como https://www.humblebundle.com/downloads?key=4vMtRuTHm53R que permiten el acceso a la cuenta a través de la url tienen una clave compuesta de 12 caracteres aleatorios alfanuméricos en minúscula (27), mayúscula(26) y numérica(10) por ello cabe un rango de posibles combinaciones de 63^12 algo inviable por tiempo y recursos además habría que contar con la posibilidad de realizar varias denegaciones de servicio, pero no por ello descartable para otras webs. 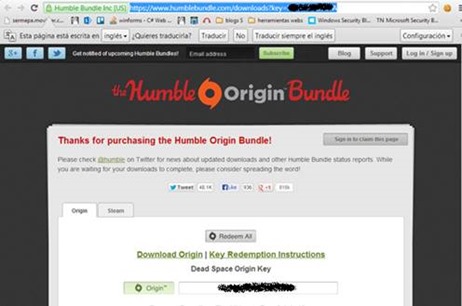 Imagen 4: Cuenta humble Antes se solía mandar al correo un email las webs donde uno se acababa de registrar con el usuario y contraseña una práctica que ya no se suele usar por el hecho de que una vez comprometido el correo un atacante podía ver esas credenciales y ahora con el método del acceso en la url existe otro vector por el que el atacante acceda a X web como usuario logeado teniendo de este modo la misma importancia que enviar las credenciales al correo, aunque no le será tan fácil al atacante que se haya colado en su correo filtrar los emails como se hacía antes con los que contenían credenciales filtrando por password, contraseña, usuario, login, ya que no hay un patrón que filtre las urls que tenga la clave en la variable
tal vez por key? Para el caso de www.humblebundle.com si hubiese servido, pero cada web tendrá su propio nombre de variable 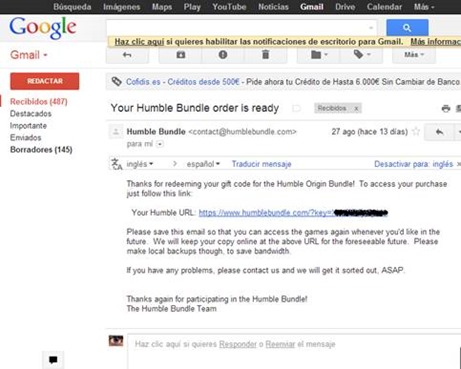 Imagen 5: Bandeja de entrada gmail Hay que tener en cuenta que cualquier usuario si guarda una url como esta es más susceptible a guardarla sin la seguridad y protección que podría emplear para guardar unas credenciales, por ello resulta más fácil robar una url con el acceso que una combinación de usuario y contraseña Fuente: http://code-disaster.blogspot.com/ |
|
|
|
|
9
|
Seguridad Informática / Nivel Web / Tips for develop "Path Traversal" Tool
|
en: 5 Septiembre 2013, 11:27 am
|
 Tips for develop "Path Traversal" Tool. By Ricardo M.R. Tips for develop "Path Traversal" Tool. By Ricardo M.R.En esta entrada voy a dar unos trucos para los que decidan desarrollar una herramienta que se aproveche de la vulnerabilidad Path Traversal o Transversal primero he de decir que no voy a explicar lo que es, si quieren saberlo pueden buscarlo en wikipedia o googleando un poco , no se trata de eso este post, si no de agilizar en la medida de lo posible la explotación automatizada de esta vulnerabilidad Para empezar voy a explicar dos restricciones a nivel de código, dos funciones que pueden (joder) hacer mas compleja su explotación. DefinicionesBasename: Regresa el nombre del archivo o directorio, por ejemplo /var/www/index.html -> regresa 'index.html' realpath: Devuelve la ruta de acceso resuelta, resolviendo las referencias de caracteres '/./', '/../' y '/' extra EstudioPara realizar el escalado de directorios en los diferentes sistemas se utilizan diferentes sintaxis ..\..\ Windows ../../ Linux ../../ Apache ./ Apache con basename en el código fuente de la app vulnerable Uno de los trucos que propongo es la de olvidar buscar ficheros windows y linux, centrándonos unicamente en la sintaxis de Apache teniendo en cuenta el basename y de esta manera si es vulnerable nos centraremos en una única sintaxis para descargar el archivo vulnerable de dentro de directorio web y de esta forma abstraernos del sistema operativo. .././ ../.././ Otra cosa a tener en cuenta es ir tan atrás como podamos en los directorios desde la primera petición ya que es posible no llegar pero seguro funciona si nos pasamos, esto no es nada nuevo, un simple recordatorio no aplicable al ejemplo anteriormente explicado: Suponiendo el siguiente caso /var/www/down/download.php?f=img.jpg "Arbitrary file download Para acceder a /etc/passwd desde el download.php (fichero vulnerable) ../../../../../../../../../../../../../../../../../../../../../../../../../../../../etc/passwd correcto ../../etc/passwd incorrecto Siendo que basta solamente con ir atrás 3 saltos ../../../etc/passwd para llegar al etc/passwd Desarrollando la AppUn Paso a Paso de un caso común: A la url se le inyecta por cada parámetro: [linux] ../../../../../../../../../../../../../../../../etc/group [windows] \\..\\..\\..\\..\\..\\..\\..\\..\\..\\..\\..\\..\\..\\..\\..\\..\\windows\\system32\\drivers\\etc\\hosts con lo cual una url tal que así http://pepe.com/?a=1&b=2terminaría variando como se aprecia a continuación: 2 peticiones en los 2 parámetros para la descarga del fichero etc/group en Linux. http://pepe.com/?a=[linux]&b=2 http://pepe.com/?a=1&b=[linux] y 2 peticiones en los 2 parámetros para la descarga del fichero hosts en Windows http://pepe.com/?a=[windows]&b=2 http://pepe.com/?a=1&b=[windows] Con Mod_Rewrite, Sin basename y sin realpath---------------- TRUCO 1--------------------------------- Ejemplo: http://localhost/PathTraversal/ptraversal.php?archivo=img.jpgEn este posible caso el fichero ptraversal.php realmente no se encuentra en ./PathTraversal/ptraversal.php ya que con mod rewrite se ha especificado que cuando se acceda a http://localhost/PathTraversal/ptraversal.phpse redirija a ./xxx/yyyy/zzzz/PathTraversal/ptraversal.php por ello se va a realizar las pruebas estándar para win y linux ../../../../../../../../../../../../../../../../etc/group \\..\\..\\..\\..\\..\\..\\..\\..\\..\\..\\..\\..\\..\\..\\..\\..\\windows\\system32\\drivers\\etc\\hosts ---------------- TRUCO 2--------------------------------- Se hace una petición para producir un error: http://xxxxx.com/download.php?file[]='Si en el Source se encuentra un FPD se obtiene la ruta interna y se concatena a la url <b>/home/jonathan/public_html/download.php</b> tal que así, logrando de esta forma tener la ruta real (absoluta). http://xxxxx.com/download.php?file=/home/jonathan/public_html/download.phpSin Mod_Rewrite, Con basename y con realpath---------------- TRUCO 1--------------------------------- Ejemplo http://localhost/PathTraversal/ptraversal.php?archivo=img.jpgPrimero se corta la url desde dominio/ hasta ? PathTraversal/ptraversal.php se añade el ./ ./PathTraversal/ptraversal.php Y a partir de aquí se intenta escalar directorios http://localhost/PathTraversal/ptraversal.php?archivo=./PathTraversal/ptraversal.php erróneo http://localhost/PathTraversal/ptraversal.php?archivo=.././PathTraversal/ptraversal.php correcto Si lo que devuelve en la descarga del fichero o en la visualización de la web contiene <? y ?> podemos decir que es vulnerable ya que nos encontramos frente a arbitrary file download o un Local File Include" (LFI). Fuente: http://code-disaster.blogspot.com/ |
|
|
|
|
10
|
Seguridad Informática / Nivel Web / iDStore lista ficheros y directorios ocultos de ficheros .DS_Store
|
en: 29 Agosto 2013, 09:21 am
|
Hoy traigo una herramienta que fue publicada en http://www.elladodelmal.com/2013/04/extraer-lista-de-urls-de-ficheros.html hace unos meses cuando aún estaba realizando las prácticas del ciclo superior de Desarrollo de Aplicaciones Web (DAW), quise algún día traerla y hoy ya toco. Glosario.DS_Store (Desktop Services Store) es un archivo oculto exclusivo del sistema operativo de Apple Inc. Mac OS X para almacenar los atributos personalizados de una carpeta, como puede ser la posición de los iconos o la imagen de fondo. Estos ficheros suelen encontrarse en paginas webs al realizar la subida de un directorio junto con los ficheros .DS_Store ocultos de un Mac OS X y por ello algunos se pueden encontrar indexados a los buscadores. Estos ficheros se puede encontrar dorkeando en Google con un dork tal que así, inurl:.ds_store intext:Bud1 o de esta otra forma ext:ds_store Bud1  Imagen 1: Busqueda con Dork Estos ficheros como se puede apreciar en la siguiente imagen tiene un Head propio de propio de ellos que contiene la cadena Bud1 además de un cuerpo en el que se encuentra un patrón al final de los nombres de ficheros y directorios Ilocblob que los identifican 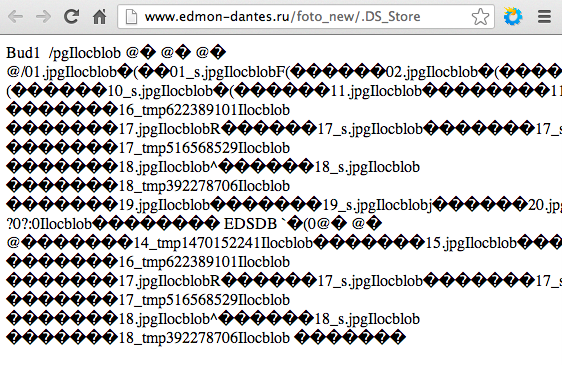 Imagen 2: Fichero .DS_Store La herramienta que he desarrollado se encuentra compilada en C# y Java además de sus correspodientes SRC donde podréis ver e investigar como funciona, esta versión no esta lo depurada que me hubiese gustado pero realiza su objetivo listando de la URL donde se encuentra el fichero .DS_Store los nombres de ficheros y directorios escondidos en el. Para un ejemplo se realizo la prueba contra esta web que además de contener dicho fichero tiene un directorio abierto, con lo cual se pueden contrastar los resultados extraídos por la herramienta y los que se listan en la propia web y es que esta herramienta es una gran alternativa a listar directorios que se encuentran protegidos y con ello no son listados. 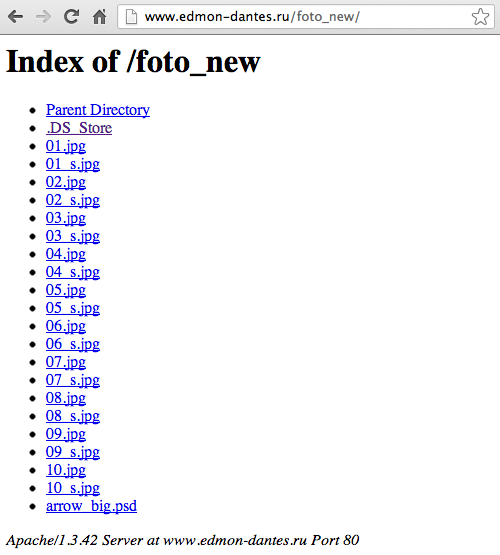 Imagen 3: Directorio abierto Una vez lanzada la aplicación se puede ver como quedo el resultado en la siguiente captura. 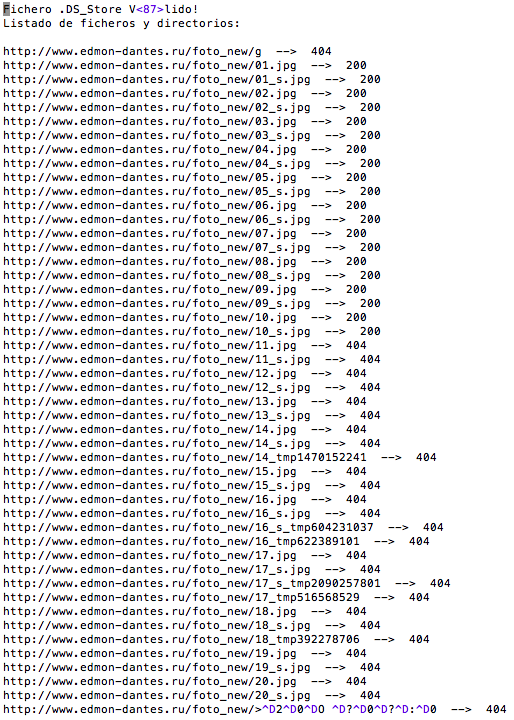 Imagen 4: Resultado de la iDStore Se puede apreciar los ficheros que en un principio estuvieron, con errores 404 y que ahora no están y los que aún continúan estando Source en C# y Java + compilados http://sourceforge.net/projects/idstore/files/Ya van 165 descargas Fuente: http://code-disaster.blogspot.com/ |
|
|
|
|
|
| |
|