[list=1] Inicio
La Idea
Inconvenientes
Pruebas
[list=2] Firefox
IExplorer
Chrome
Safari[/list]
Más ideas
Planteamiento del ataque[/list] InicioEl tema del siguiente articulo como bien dice el titulo se trata de la recopilación de información del sistema mediante un fichero HTML que se encuentre almacenado en local.
Esta técnica que hago pública pretende ser una alternativa a la recopilación de información de un sistema mediante un tipo de fichero no comúnmente utilizado para este fin, que va a resultar menos sospechoso que un binario, evidentemente esta técnica no se puede comparar con la cantidad de información que puede recabar otras herramientas spyware pero como bien digo es una alternativa.
La ideaLa idea básicamente es utilizar el esquema URI file:// para apuntar mediante una etiqueta HTML a un recurso de la maquina en la que se abre el fichero HTML y apoyándose en javascript, más concretamente en los eventos o en el tiempo de retardo de los mismo o en la ausencia de estos, poder identificar si ese recurso existe o no, más delante se detallará más este concepto.
Inconvenientes javascript: Puede ser que se esté bloqueando la ejecución de javascript en la página web que recoge la información del sistema.
Esquema URI file://: El inconveniente de este esquema URI es que no puede ser utilizado si la aplicación web que lo utiliza para hacer referencia a un fichero la brinda un servidor web, o lo que es lo mismo, solo se puede utilizar si la aplicación web que utiliza este esquema URI se abre desde la máquina de la víctima.
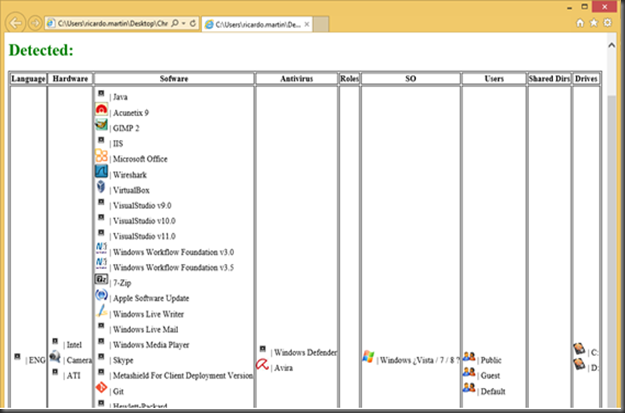
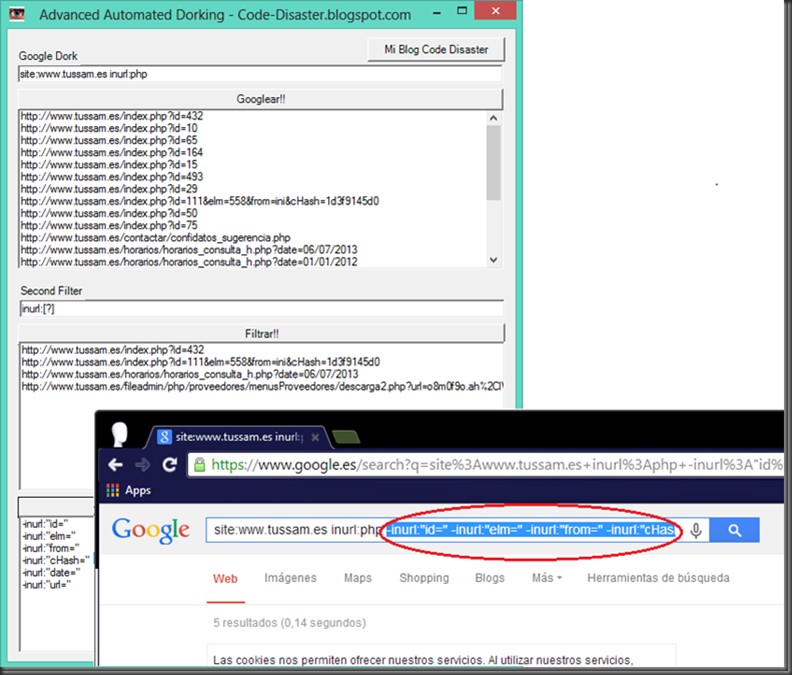
PruebasCon IExplorer es posible detectar los recursos internos de un sistema en el ejemplo siguiente, detectar los directorios de aplicaciones cuando el evento javascript onLoad no es llamado, es decir que cuando un recurso no existe el evento onLoad es llamado y por el contrario cuando existe no lo es.
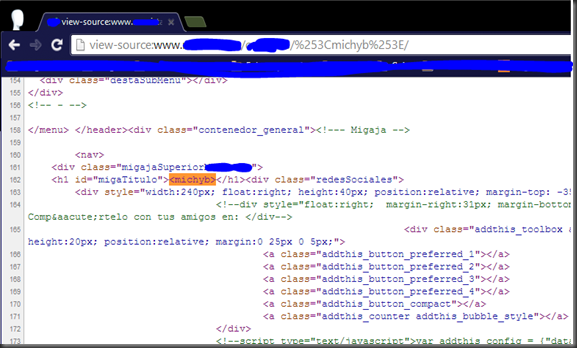
En la imagen que se muestra a continuación se puede ver una lista que se determinar cómo se ha explicado antes, dependiendo de si el navegador no llama al evento onLoad cuando se haga referencia a un directorio existente mediante un iframe.
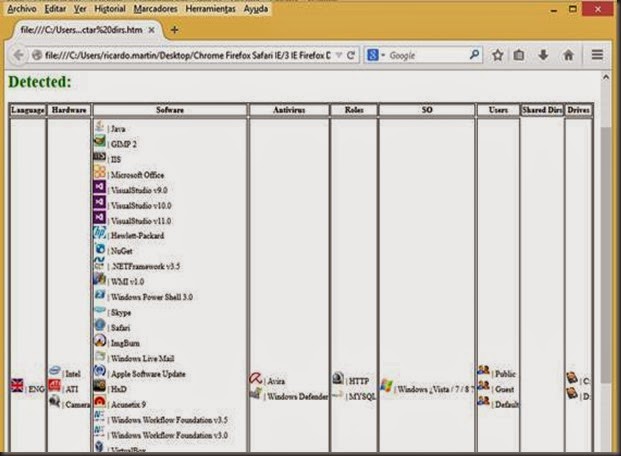
<iframe src=file://C:/ onLoad=alert(NO EXISTE)>Con Firefox al contrario que con IExplorer es posible determinar de si el directorio al que se apunta existe SI el evento onLoad es llamado.
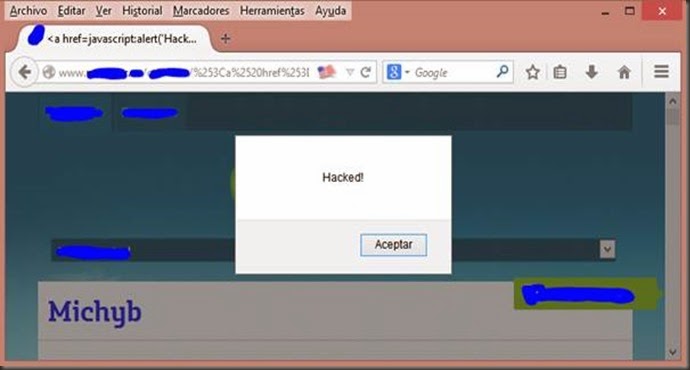
<iframe src=file://C:/ onLoad=alert(EXISTE)>Como conclusión para IExplorer y Firefox se puede decir según las imágenes que es posible determinar: el lenguaje del sistema, el hardware en base al software instalado, software instalado, antivirus, sistema operativo, por fuerza bruta usuarios en el sistema, directorios compartidos, unidades de disco, etc.
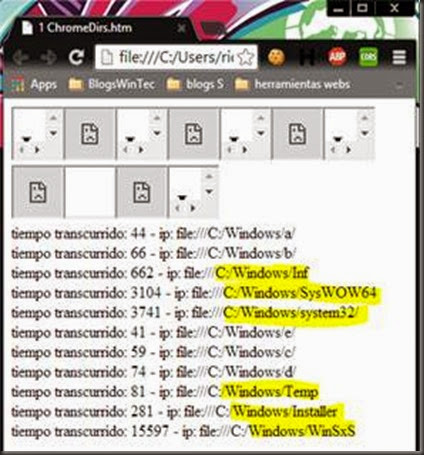
Para Chrome no es tan fácil ya que no se puede en base a eventos determinar nada ya que los eventos son llamados existan o no los directorio utilizando iframe, sin embargo si se puede determinar los directorios con grandes cantidades de ficheros y subdirectorios en base al tiempo de retraso en el renderizado de los mismos.
En el siguiente ejemplo se apunta a cinco directorios que no existen y a seis que si, como se puede apreciar los que si existen y que además tienen gran cantidad de elementos tardan mucho más en llamar al evento onLoad que va a servir para calcular el tiempo entre la creación del iframe y el final de la cargar del recurso.
Por ultimo hablar sobre el tratamiento de Safari que cuando la etiqueta apunta a un directorio desde un iframe, el funcionamiento de este se traducía en lanzar un explorador de Windows apuntando al directorio que se había establecido en el atributo src del iframe, entonces dejando de lado la posibilidad de detectar los directorios de forma discreta lo que quedaba era realizar un ataque que se basa en añadir una cantidad ingente de iframe apuntando a directorios existentes del sistema por ejemplo a la unidad C: con ello se consigue que el escritorio de la víctima se vea inundado de ventanas del explorador de Windows.
Más ideasEstos problemas de eventos, ausencias de ellos o retraso en los mismos, o como sucede con Safari que abre un explorador de Windows, no suceden cuando se apunta a imágenes u otro tipo de ficheros según el tipo de etiqueta utilizada.
<img src="file://C:/test.pngs" onload="alert('existe')">
<img src="file://C:/no-existe.pngs" onload="alert('existe')">Funcional en Chrome, IExplorer, Safari, Firefox.
De esta forma se podría realizar un script que además de apuntar a directorios apuntase a imágenes, css, js etc para obtener más información del sistema.
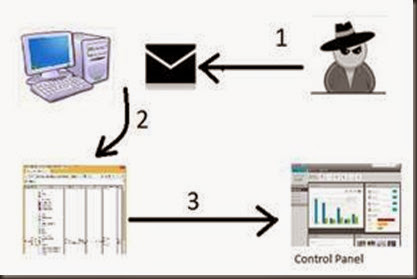
Planteamiento del ataqueY para acabar el articulo exponer un simple escenario de ataque donde intervienen un atacante(1) que envía un correo donde adjunta un fichero HTML(2) que va a recabar información del sistema de la víctima y este enviara a un panel de control(3) toda esa información donde a posterior visualizara el atacante.
Fuente:
http://code-disaster.blogspot.com.es